Im Fokus: KI-Chat , Spiele wie Retro , Standortwechsler , Roblox entsperrt
Im Fokus: KI-Chat , Spiele wie Retro , Standortwechsler , Roblox entsperrt
Die Welt der KI-Sprachgenerierung hat bemerkenswerte Fortschritte erlebt und verändert, wie wir Technik hören und mit ihr interagieren. KI-Stimmgeneratoren nutzen hochmoderne Algorithmen der künstlichen Intelligenz, um lebensechte und ausdrucksstarke Stimmen zu erzeugen, die für verschiedene Anwendungen eingesetzt werden können. Diese Tools bieten beeindruckenden Realismus und Vielseitigkeit, sei es für persönliche Assistenten, die Erstellung von Audioinhalten oder Sprachsynthese in unterschiedlichen Branchen. Dieser umfassende Artikel untersucht die Top 7 KI‑Sprachgeneratoren, stellt ihre Funktionen, Vor- und Nachteile vor und zeigt einfache Schritte, wie man sie effektiv nutzt. Durch das Verständnis der jeweiligen Besonderheiten jedes Tools können Nutzer fundierte Entscheidungen auf Basis ihrer spezifischen Bedürfnisse und Anforderungen treffen.

Siri ist ein von Apple entwickelter Sprachassistent, der personalisierte Unterstützung bietet und verschiedene Aufgaben über Sprachbefehle erledigt. Es nutzt fortschrittliche Algorithmen zur Verarbeitung natürlicher Sprache und maschinellen Lernens, um Benutzeranfragen zu verstehen und darauf zu reagieren. Das Beste an Siri ist, dass es sich um einen kostenlosen KI-Sprachgenerator für iPhone-Benutzer handelt.
Während Siri in erster Linie als KI-Sprachassistent fungiert, verfügt es auch über einen Sprachgenerator, der natürlich klingende Sprache erzeugen kann. Der Sprachgenerator von Siri ist für seine Klarheit, Geschmeidigkeit und hochwertige Ausgabe bekannt. Es verwendet Deep-Learning-Techniken, um menschenähnliche Stimmen zu erzeugen, sodass Benutzer über Sprachbefehle mit Siri interagieren und Antworten auf natürliche und intuitive Weise erhalten können. Dem Sprachgenerator von Siri fehlen jedoch umfangreiche Anpassungsmöglichkeiten. Benutzer können Stimmeigenschaften, Akzente oder Sprachstile nicht ändern. Es verfügt über eine KI-Sprachwechslerfunktion, die Sie manuell nach Ihren Wünschen ändern können. Außerdem Abhängigkeit von der Internetverbindung: Siri ist in hohem Maße auf die Internetverbindung angewiesen, um Sprachausgaben zu generieren. Dies kann ein Nachteil sein, wenn Sie Siri in Gebieten mit schlechter oder keiner Internetverbindung verwenden.

Am besten geeignet für: Siri ist am besten für iOS‑Nutzer geeignet, die Sprachbefehle für Aufgaben wie das Tätigen von Anrufen, das Senden von Nachrichten, das Erstellen von Erinnerungen, das Abrufen von Wegbeschreibungen und den freihändigen Zugriff auf Informationen verwenden möchten.
Plattformen: Siri ist auf iOS‑Geräten verfügbar, einschließlich iPhones, iPads und iPod Touch, sowie auf Apples Smart Speaker HomePod.
Preis: Siri ist vorinstalliert und auf kompatiblen Apple‑Geräten kostenlos verfügbar.
Einfache Schritte
Lassen Sie uns Siri aktivieren, indem wir die Home-Taste (auf älteren iOS‑Geräten) oder die Seitentaste (auf neueren iPhones ohne Home‑Taste) gedrückt halten oder den Sprachbefehl Hey Siri verwenden.
Sobald Siri aktiviert ist, warten Sie auf die Sprachanzeige und stellen Sie Ihre Frage oder geben Sie einen Befehl. Sie können zum Beispiel sagen: Wie ist das Wetter heute? oder Sende eine Nachricht an John.
Siri wird Ihre Anfrage bearbeiten und eine Antwort geben oder die angeforderte Aktion ausführen.
Murf.ai ist ein AI-Text-to-Voice-KI-Sprachgenerator, der fortschrittliche Algorithmen nutzt, um geschriebenen Text in natürlich klingende Sprache umzuwandeln. Es bietet hochwertige Sprachsynthese und eine Reihe anpassbarer Sprachoptionen für verschiedene Anwendungen. Darüber hinaus ist Murf.ai ein KI-Sprachgenerator, der sich auf die Erstellung personalisierter, benutzerdefinierter Stimmen spezialisiert hat. Es nutzt Deep-Learning-Algorithmen, um die einzigartigen Stimmmerkmale einer Person zu analysieren und nachzuahmen, sodass Benutzer Sprache erzeugen können, die ihrer Stimme sehr ähnlich ist. Die Technologie von Murf.ai ist darauf ausgelegt, subtile Nuancen, Intonationen und Sprachmuster zu erfassen, was zu einer äußerst realistischen und personalisierten Sprachausgabe führt. Dennoch erfordert Murf.AI, dass Benutzer ihre aufgezeichneten Sprachproben bereitstellen, um personalisierte Stimmen zu generieren. Dies kann bei Personen, die zögern, ihre Sprachdaten mit Diensten Dritter zu teilen, zu Datenschutzbedenken führen.

Am besten geeignet für: murf.ai eignet sich für Privatpersonen und Unternehmen, die zuverlässige Sprachsynthese‑Lösungen suchen. Es kann in verschiedenen Bereichen eingesetzt werden, etwa für Hörbuch‑Narration, die Produktion von Voiceovers, virtuelle Assistenten und Barrierefreiheits‑Anwendungen.
Plattformen: murf.ai ist eine webbasierte Plattform, auf die über einen Webbrowser auf Computern und mobilen Geräten zugegriffen wird. Der Preis reicht von $20 bis $99.
Preis: murf.ai bietet abonnementbasierte Preispläne mit unterschiedlichen Stufen, abhängig von Nutzung und Funktionsumfang.
Einfache Schritte
Besuchen Sie die murf.ai‑Website und erstellen Sie ein Konto oder loggen Sie sich ein, wenn Sie bereits eines besitzen.
Greifen Sie auf die Text-zu-Sprache-Schnittstelle zu, um den gewünschten Text einzugeben, der in Sprache umgewandelt werden soll.
Passen Sie die Stimmparameter wie Tonhöhe, Geschwindigkeit und Emotion an Ihre Vorlieben an.
Klicken Sie auf die Schaltfläche Generate oder Play, um den Sprachsynthesevorgang zu starten.
Sobald die Sprachgenerierung abgeschlossen ist, können Sie die synthetisierte Sprachdatei in verschiedenen Formaten in der Vorschau anzeigen und herunterladen.
Lyrebird ist ein KI-Stimmengenerator, der für seine Fähigkeit bekannt ist, menschliche Stimmen mit beeindruckender Genauigkeit nachzubilden. Aus diesem Grund wird es als bester AI Voice Clone ausgezeichnet. Mithilfe von Deep-Learning-Techniken kann Lyrebird Sprache erzeugen, die einer bestimmten Person sehr ähnlich ist, oder die Stimme einer Person auf der Grundlage einiger Minuten der aufgezeichneten Audiodaten nachahmen. Es wurde für verschiedene Anwendungen verwendet, darunter Voice-Over, virtuelle Assistenten und Barrierefreiheitsdienste. Kurz gesagt, Lyrebird ist eine KI-Plattform zur Sprachgenerierung, die realistische und anpassbare synthetische Stimmen bietet. Es verwendet tiefgreifende Algorithmen, um menschliche Sprachmuster zu analysieren und nachzuahmen, sodass Benutzer hochwertige Stimmen für verschiedene Anwendungen generieren können.
Andererseits wirft die Fähigkeit der Lyrebird-KI, Stimmen mit hoher Genauigkeit nachzuahmen, ethische Bedenken auf. Es besteht die Gefahr eines Missbrauchs, wie z. B. Stimmfälschung oder die Generierung synthetischer Stimmen ohne Einwilligung. Außerdem gibt es eine Frage zum Thema „Geistiges Eigentum“. Die Technologie von Lyrebird AI ermöglicht es Benutzern, die Stimme einer anderen Person ohne Erlaubnis zu reproduzieren und zu verwenden. Dies kann zu Streitigkeiten über Urheberrechte und geistiges Eigentum führen. Insgesamt ist dieses Tool ein großartiger KI-Sprachreplikator.

Am besten geeignet für: Ideal für Entwickler, Content‑Creator und Unternehmen, die anpassbare, lebensechte synthetische Stimmen suchen. Es kann in Sprachassistenten, der Produktion von Audiocontent, Virtual‑Reality‑Erlebnissen und mehr eingesetzt werden.
Plattformen: Lyrebird ist eine webbasierte Plattform, auf die über einen Webbrowser auf Desktop‑ und Mobiltelefonen zugegriffen wird.
Preis: $18.00
Einfache Schritte
Melden Sie sich bei Ihrem Lyrebird‑Konto an, nachdem Sie eines erstellt haben. Öffnen Sie dann das Fenster Voice Generation und geben Sie den Text ein, der in Sprache umgewandelt werden soll.
Wählen Sie die gewünschten Stimmqualitäten wie Geschlecht, Alter und emotionalen Stil.
Klicken Sie auf die Schaltfläche Generate oder Play, um den Sprachgenerierungsprozess zu starten.
WaveNet ist ein auf Deep Learning basierender KI-Sprachgenerator, der von DeepMind, einer Tochtergesellschaft von Google, entwickelt wurde. Es nutzt eine Technik, die als generative Modellierung bekannt ist, um äußerst realistische und natürlich klingende Sprache zu synthetisieren. WaveNet ist dafür bekannt, die feinen Details menschlicher Sprache zu erfassen, einschließlich Betonung, Atemzügen und sogar Hintergrundgeräuschen, was zu einer äußerst ausdrucksstarken und lebensechten Sprachausgabe führt. Der Sprachgenerierungsprozess von WaveNet AI kann jedoch rechenintensiv sein und erhebliche Rechenleistung und Zeit erfordern, um qualitativ hochwertige Ausgaben zu generieren. Dies kann die Echtzeit-Anwendbarkeit in bestimmten Szenarien einschränken. Es fehlt auch eine feinkörnige Kontrolle. Die Sprachgenerierung von WaveNet AI basiert auf Deep-Learning-Modellen, die keine differenzierte Kontrolle über die Änderung bestimmter Stimmeigenschaften bieten. Das Lustige daran ist, dass es ein KI-Stimmengenerator für Rapper sein kann, wenn wir es in seinen Einstellungen einstellen. Benutzer haben nur begrenzte Möglichkeiten, die generierten Stimmen über die Trainingsdaten hinaus anzupassen. Darüber hinaus nutzt es eine tiefe neuronale Netzwerkarchitektur, um äußerst natürliche und ausdrucksstarke Sprachwellenformen zu erzeugen, die es zumindest zum Besten machen.
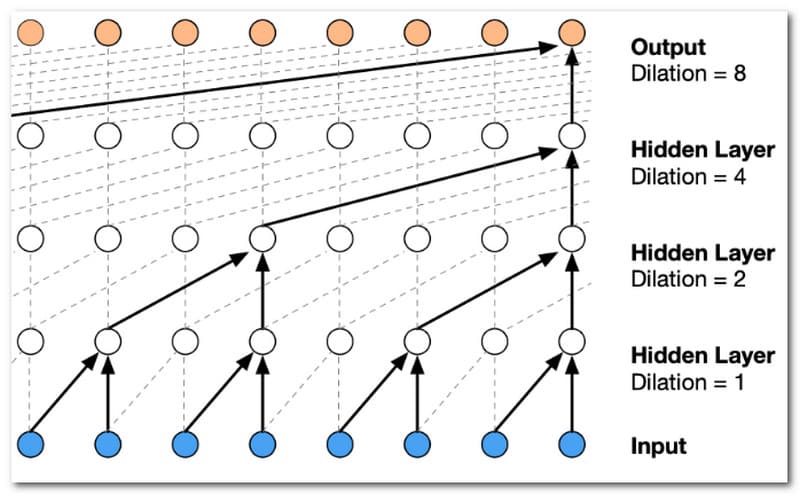
Am besten geeignet für: WaveNet eignet sich am besten für Anwendungen mit hochpräziser und menschlich klingender Sprachsynthese. Es wird häufig in virtuellen Assistenten, bei der Voiceover‑Produktion, der Hörbuch‑Narration und anderen Szenarien eingesetzt, in denen natürlich klingende Stimmen entscheidend sind.
Plattformen: WaveNet ist eine Technologie, die in verschiedene Plattformen und Anwendungen integriert werden kann. Sie wurde in Diensten wie dem Google Assistant implementiert und ist auch als API verfügbar, damit Entwickler sie in ihre Projekte einbinden können.
Preis: Die Preise für WaveNet variieren je nach konkreter Implementierung oder Integration. Google bietet unterschiedliche Preismodelle für seine verschiedenen Dienste an, die WaveNet nutzen. Es ist ab $4.0 verfügbar.
Einfache Schritte
Bestimmen Sie die konkrete Plattform oder Anwendung, die WaveNet für die Stimmgenerierung nutzt.
Wenn Sie eine integrierte Plattform wie den Google Assistant verwenden, aktivieren Sie die Spracheingabefunktion oder lösen Sie die Sprachbefehl‑Funktion aus.
Sprechen Sie oder geben Sie den Text ein, den Sie in Sprache umwandeln möchten.
Die Plattform oder Anwendung verarbeitet die Eingabe mithilfe der WaveNet-Algorithmen und generiert die entsprechende Sprachwellenform. Die synthetisierte Sprache wird abgespielt oder je nach Bedarf innerhalb der Plattform oder Anwendung verwendet.
Amazon Polly ist ein cloudbasierter Text-to-Speech-Dienst, der von Amazon Web Services (AWS) bereitgestellt wird. Es bietet lebensechte Stimmen und erweiterte Sprachsynthesefunktionen, sodass Entwickler und Unternehmen Text in natürlich klingende Sprache umwandeln können. Das bedeutet, dass es auch als KI-Sprachleser verwendet werden kann. Amazon Polly bietet eine große Auswahl an Stimmen in mehreren Sprachen und stellt Entwicklern benutzerfreundliche APIs zur Integration von Sprachgenerierungsfunktionen in ihre Anwendungen zur Verfügung. Es bietet hochwertige Sprachsynthese mit verschiedenen Anpassungsoptionen.

Am besten geeignet für: Amazon Polly ist ideal für Entwickler und Unternehmen, die skalierbare, anpassbare Text‑zu‑Sprache‑Lösungen suchen. Es kann in Anwendungen wie Sprachassistenten, E‑Learning‑Plattformen, Podcast‑Produktion, Barrierefreiheits‑Funktionen und mehr eingesetzt werden.
Plattformen: Amazon Polly ist ein Cloud‑basierter Dienst, auf den über die AWS Management Console oder programmatisch über die API zugegriffen wird.
Preis: $40.00. Amazon Polly bietet ein nutzungsabhängiges Preismodell, bei dem Nutzer auf Basis der verarbeiteten Zeichenzahl und der gewählten Stimme abgerechnet werden. Ausführliche Preisinformationen finden Sie in der Preisdokumentation zu Amazon Polly.
Einfache Schritte
So erstellen Sie KI‑Stimmen mit Polly: Melden Sie sich in der AWS Management Console an oder nutzen Sie die Amazon Polly API, um zu beginnen.
Wählen Sie für die Sprachsynthese die gewünschte Stimme und Sprache aus.
Geben Sie den Text, der in Sprache umgewandelt werden soll, entweder manuell oder programmgesteuert ein.
Rufen Sie die passende API‑Methode auf oder klicken Sie in der Konsole auf die entsprechende Schaltfläche, um den Text‑zu‑Sprache-Konvertierungsprozess zu starten.
Baidu Research hat Deep Voice entwickelt, eine KI-basierte Sprachsynthesetechnik. Deep-Learning-Techniken generieren aus Texteingaben echte und ausdrucksstarke Stimmen. Deep Voice AI ist ein von OpenAI entwickelter KI-Sprachgenerator, der Deep-Learning-Techniken nutzt, um menschenähnliche Sprache zu erzeugen. Es nutzt eine Kombination aus neuronalen Netzen und Sprachsynthesealgorithmen, um natürlich klingende Stimmen zu erzeugen. Deep Voice AI kann aus großen Datensätzen lernen und Sprache in mehreren Sprachen mit unterschiedlichen Stimmstilen und Akzenten erzeugen.

Am besten geeignet für: Deep Voice ist für Anwendungen geeignet, die hochwertige und anpassbare Sprachsynthese erfordern. Es kann in virtuellen Assistenten, bei der Voiceover‑Produktion, der Sprachsynchronisation und anderen Szenarien eingesetzt werden, in denen realistische und menschenähnliche Stimmen essenziell sind.
Plattformen: Deep Voice ist eine Technologie, die in verschiedene Plattformen und Anwendungen integriert werden kann. Sie wird typischerweise als API implementiert, die Entwickler nutzen können, um Deep‑Voice‑Funktionalität in ihre Projekte einzubinden.
Preis: $19
Einfache Schritte
Bestimmen Sie den Text, den Sie mit Deep Voice AI in Sprache umwandeln möchten. Bereiten Sie den Text entweder programmatisch innerhalb Ihrer Anwendung oder über eine Nutzereingabe vor.
Erstellen Sie eine API‑Anfrage, um die Texteingabe an die Deep Voice AI API zur Sprachsynthese zu senden.
Verarbeiten Sie nach Erhalt der API‑Antwort die synthetisierte Sprachausgabe.
Resemble AI ist eine KI-gestützte Sprachsyntheseplattform, die es Benutzern ermöglicht, realistische und personalisierte Stimmen für verschiedene Anwendungen zu erstellen. Es nutzt Deep-Learning- und KI-Sprachsynthesetechniken, um hochwertige, natürlich klingende Sprache zu erzeugen. Resemble AI ist ein KI-Sprachgenerator, der sich auf die Erstellung benutzerdefinierter Stimmen für verschiedene Anwendungen wie virtuelle Assistenten, Spiele und Medienproduktion spezialisiert hat. Es verwendet Deep-Learning-Algorithmen, um die einzigartigen Eigenschaften der Stimme einer Person zu analysieren und zu reproduzieren. Die Technologie von Resemble AI ermöglicht es Benutzern, synthetische KI-Stimmen zu erstellen, die bestimmten Personen sehr ähnlich sind, was zu einer hochgradig personalisierten und authentischen Sprachausgabe führt. Es bietet eine benutzerfreundliche Oberfläche und stellt Entwicklern APIs zur Integration der Spracherzeugungsfunktionen in ihre Projekte zur Verfügung.

Am besten geeignet für: Resemble AI eignet sich für Privatpersonen, Entwickler und Unternehmen, die anpassbare und ausdrucksstarke Sprachsynthese‑Lösungen suchen. Es kann in der Voiceover‑Produktion, in virtuellen Assistenten, im Gaming, in Animationen, bei der Hörbuch‑Narration und anderen Anwendungen eingesetzt werden, in denen einzigartige und personalisierte Stimmen gewünscht sind.
Plattformen: Resemble AI ist eine Cloud‑basierte Plattform, die APIs und SDKs für eine einfache Integration in verschiedene Plattformen und Programmiersprachen bereitstellt.
Preis: $29.00
Einfache Schritte
Erstellen Sie ein Konto auf der Resemble AI-Website und erwerben Sie die erforderlichen API-Anmeldeinformationen.
Wählen Sie den gewünschten Grad der Stimmmodifikation und erfassen Sie alle erforderlichen Trainingsdaten. Installieren Sie dann das Resemble AI SDK oder die Bibliotheken für die Programmiersprache Ihrer Wahl.
Authentifizieren Sie Ihre API-Abfragen mithilfe der bereitgestellten Anmeldeinformationen. Senden Sie den Text und die Anpassungsparameter über API oder SDK an die Resemble AI-Plattform. Rufen Sie abschließend die synthetisierte Sprachausgabe ab und verwenden Sie sie nach Bedarf in Ihrer Anwendung oder Ihrem Dienst.
Ist Voice.ai sicher?
Nach Angaben des Benutzers sind einige Sprach-KIs sicher zu verwenden, während dies bei anderen Tools nicht der Fall ist. Um die Sicherheit einer Plattform oder Website wie Voice.ai zu beurteilen, wird empfohlen, gründliche Recherchen durchzuführen, Benutzerrezensionen und Erfahrungsberichte zu lesen, deren Datenschutzrichtlinien und Nutzungsbedingungen zu bewerten und Faktoren wie den Ruf der Plattform, Sicherheitsmaßnahmen usw. zu berücksichtigen Kundendienst. Sie können auch prüfen, ob vertrauenswürdige Behörden die Plattform verifiziert haben oder über Zertifizierungen verfügen, die ihre Legitimität und ihr Engagement für die Benutzersicherheit belegen.
Ist Voice.ai seriös?
Zuallererst: Unsere KI-Stimmen sind legal? Die schnelle Antwort ist ja. Es steckt jedoch noch viel mehr dahinter. Die Rechtmäßigkeit dieser Technologie hängt von der Art ihrer Nutzung und der jeweiligen Gerichtsbarkeit ab.
Wofür können KI‑Stimmgeneratoren verwendet werden?
KI-Sprachgeneratoren haben ein breites Anwendungsspektrum. Sie können für die Voiceover-Produktion in Filmen, Fernsehsendungen und Werbespots, die Erstellung virtueller Assistenten mit einzigartigen Stimmen, das Hinzufügen von Erzählungen zu Hörbüchern, die Verbesserung der Zugänglichkeit für sehbehinderte Menschen, die Verbesserung des Spielerlebnisses mit interaktiven und realistischen Charakterstimmen und vieles mehr verwendet werden. Wenn Sie mit dem Burger King AI Voice Generator vertraut sind, wird er hauptsächlich zum Anpassen von Stimmen, für Werbung, Podcasting, zum Anhören von Hörbüchern wie Hayasaka Voice Actor und mehr verwendet. Eine andere ist die Val Kilmer AI Voice, die vorschlägt, ihre Projekte nach einer Krebsdiagnose fortzusetzen. Tatsächlich ist es für verschiedene Zwecke nützlich.
Sind KI‑generierte Stimmen von echten menschlichen Stimmen nicht zu unterscheiden?
Obwohl sich KI-generierte Stimmen in den letzten Jahren erheblich verbessert haben, weisen sie möglicherweise immer noch subtile Unterschiede auf, die geschulte Zuhörer erkennen können. Fortschritte bei der KI-Stimmenerzeugung schließen jedoch weiterhin die Lücke zwischen synthetischen und menschlichen Stimmen, wodurch der Unterschied in vielen Fällen weniger deutlich wird.
Können KI‑Stimmgeneratoren bestimmte Stimmen imitieren?
Einige KI-Sprachgeneratoren können bestimmte Stimmen nachahmen, beispielsweise von Prominenten oder historischen Persönlichkeiten, indem sie die Modelle anhand gezielter Daten trainieren. Wir haben Joe Bidens KI-Stimme, Trumps KI-Stimme, Elon Musks Stimme und weitere berüchtigte Personen als konkrete Beispiele. Die Qualität und Genauigkeit der Stimmnachahmung kann jedoch je nach den verfügbaren Trainingsdaten und der Komplexität der nachgebildeten Stimme variieren. Deshalb ist das AI Voice Meme überhaupt nicht zu empfehlen.
Abschluss
Zusammenfassend lässt sich sagen, dass die KI-Sprachgenerierung verschiedene Tools und Plattformen bietet, die es Benutzern ermöglichen, hochwertige synthetische Stimmen für verschiedene Anwendungen zu erstellen. Jedes Tool hat seine einzigartigen Funktionen, Vorteile und Einschränkungen. Bei der Auswahl des besten KI-Sprachgenerators für Ihre Anforderungen müssen Sie Preis, Plattformkompatibilität, Benutzerfreundlichkeit, Sprachqualität und Anpassungsoptionen berücksichtigen. In diesem Artikel wurden mehrere bekannte Tools zur KI-Sprachgenerierung untersucht, darunter Siri, murf.ai, Lyrebird, WaveNet, Amazon Polly, Deep Voice und Resemble AI. Jedes Tool hat seine Stärken und Schwächen und richtet sich nach den Anforderungen und Vorlieben der Benutzer.
Fanden Sie dies hilfreich?
391 Stimmen

Character.AI Review: Kreativität in der KI-Welt freisetzen
KI
YouChat Detaillierte Überprüfung: Ein unglaubliches KI-Tool für alle
KI
ChatGPT Review: Ist ein sicherer und effektiver KI-Assistent?
KI
Top 9 KI-Chatbots im Online-Test: Funktionen, Preise, Vor- und Nachteile
KI

