Im Fokus: KI-Chat , Spiele wie Retro , Standortwechsler , Roblox entsperrt
Im Fokus: KI-Chat , Spiele wie Retro , Standortwechsler , Roblox entsperrt
Haben Sie genug von endlosen KI-Bildtools?
Stable Diffusion positioniert sich als eine “Freiheits”-Lösung für die KI-Bilderzeugung. Wenn du nach einem leistungsstarken Text-zu-Bild-Modell suchst, das hochwertige Bilder auf Basis deiner Textbeschreibungen generieren kann, wirst du möglicherweise darauf stoßen oder entsprechende Empfehlungen erhalten.
In einem schnell wachsenden Bereich mit ähnlichen Modellen und Konkurrenten wie Midjourney, Seedance und Veo 3 fragen Sie sich möglicherweise: Ist Stable Diffusion Ihre Zeit wert oder liefert Stable Diffusion wirklich professionelle Ergebnisse?
Diese Stable-Diffusion-Review liefert alle notwendigen Informationen über dieses KI-Bilderzeugungsmodell und beantwortet genau diese Frage.

Inhaltsverzeichnis
Stable Diffusion ist ein flexibles Deep-Learning-Text-zu-Bild-Modell, das von Stability AI entwickelt wurde. Es basiert auf Diffusionstechnologie (veröffentlicht im Jahr 2022), die Textbeschreibungen in visuelle Darstellungen umwandeln kann. Das Modell nutzt einen CLIP ViT-L/14-Text-Encoder, um hochwertige Bilder als Antwort auf Prompts zu erzeugen.
Im Vergleich zu früheren Diffusionsmodellen reduziert die neueste Version Stable Diffusion 3.5 den Speicherbedarf erheblich. Sie zeichnet sich durch eine große architektonische Innovation aus, indem sie den Diffusionsprozess in einem latenten Raum implementiert. Frühere Modelle arbeiten direkt im Bildraum.
Dank des technischen Durchbruchs und seines Open-Source-Charakters hat Stable Diffusion schnell eine viel breitere Benutzerbasis angezogen, darunter Entwickler, Forscher, einzelne Schöpfer und Unternehmensbenutzer.
• Laufende Verbesserungen durch Versionsupdates. Seit seiner ersten Veröffentlichung hat dieses Text-zu-Bild-Generierungsmodell eine erhebliche Weiterentwicklung durchlaufen. Hauptversionen sind Stable Diffusion 1.5, 2.0, 2.1, 3.0 und die aktuelle 3.5-Serie. Sie haben wesentliche Verbesserungen in verschiedenen Aspekten gebracht, darunter Ausgabequalität, Promptverständnis und Generierungsfähigkeiten.
• Mehrere Modellversionen. Mehrere spezialisierte Modelle sind darauf ausgelegt, unterschiedliche Nutzerbedürfnisse zu erfüllen. Das neueste Basismodell ist Stable Diffusion 3.5. Es bietet erhebliche Verbesserungen gegenüber früheren Versionen. Derzeit gibt es vier Hauptversionen in der Stable-Diffusion-Familie: Stable Diffusion 3.5 Large, Large Turbo, Medium und Flash.
• Fortschrittliches Promptverständnis. Das aktuelle Stable Diffusion 3.5 verfügt über eine ausgefeilte Architektur mit mehreren Text-Encodern, die es ihm ermöglicht, komplexere und detailliertere Prompts effektiver zu verarbeiten. Es kann Textbeschreibungen mit einer Länge von bis zu 10.000 Zeichen verarbeiten. Dies ermöglicht es den Nutzern, detailliertere Beschreibungen zu liefern. Gleichzeitig kann Stable Diffusion hochwertigere und präzisere Ergebnisse erzeugen.
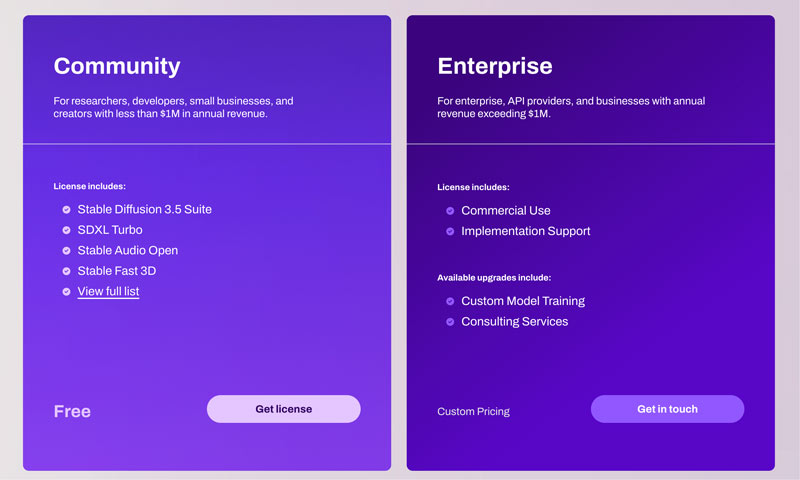
• Kommerzielle und kreative Flexibilität. Stable-Diffusion-3.5-Modelle werden unter der Stability AI Community License und der Enterprise License veröffentlicht. Das erlaubt sowohl kommerzielle als auch nichtkommerzielle Nutzung. Für die meisten Gelegenheitnutzer, wie Forscher, Entwickler und kleine Unternehmen mit einem Jahresumsatz von weniger als 1 Mio. USD, ist die Nutzung von Stable Diffusion frei und ohne Einschränkungen möglich. Nutzer können die KI frei an ihre spezifischen Bedürfnisse und künstlerischen Stile anpassen.
Wie bereits erwähnt, ist Stable Diffusion aufgrund seiner Vielseitigkeit für fast alle Benutzer geeignet. Sowohl Entwickler, Forscher, Designer, Digitalkünstler, KI-Hobbyisten als auch Studenten können von seinen Möglichkeiten erheblich profitieren.
Das neueste Modell Stable Diffusion 3.5 verfügt über erweiterte Funktionen zur Erzeugung feinerer Bilddetails. Die generierten Fotos weisen häufig präzise Beleuchtung und Motive auf. Darüber hinaus kann es den spezifischen Kunststil basierend auf Ihren Vorgaben besser anpassen.
Für die meisten Bilderzeugungsmodelle können Bereiche wie menschliche Hände und Gesichtszüge eine besondere Herausforderung darstellen. Mit der Einführung eines 16-Kanal-VAE können diese häufigen Artefakte und Unvollkommenheiten effektiv behoben werden. Stabile Diffusion eignet sich gut zur Darstellung präziser Lichteffekte.
Trotz dieser Verbesserungen weist Stable Diffusion weiterhin Schwächen auf. Insbesondere bei Ganzkörper-Renderings stößt das Modell weiterhin auf gewisse Herausforderungen. Wie andere KI-basierte Bildgenerierungsmodelle liefert Stable Diffusion häufig unerwartete Ergebnisse, insbesondere bei der Generierung vollständiger menschlicher Figuren. Die aktuelle Version Stable Diffusion 3.5 eignet sich gut für Nahaufnahmen, Porträts und verschiedene nicht-menschliche Motive.
Die Effizienz von Stable Diffusion variiert je nach verwendeter Modellversion, Hardware, Ausgabeeinstellungen und Eingabeaufforderungen. Mit einer leistungsstarken NVIDIA-GPU können Sie in der Regel problemlos in 5–15 Sekunden ein Standardbild im Format 1024 x 1024 erstellen. Stable Diffusion ist besser als viele Alternativen und ermöglicht es Benutzern, Modelle anhand eigener Datensätze zu trainieren und zu optimieren. Dies ist besonders für professionelle Anwender wertvoll.
Im Vergleich zu den Vorgängermodellen ist die aktuelle Stable Diffusion 3.5 deutlich einfacher zu bedienen. Wie einfach die Bedienung ist, hängt jedoch stark von Ihren technischen Fähigkeiten, Ihrem Erfahrungsniveau und der gewählten Benutzeroberfläche ab.
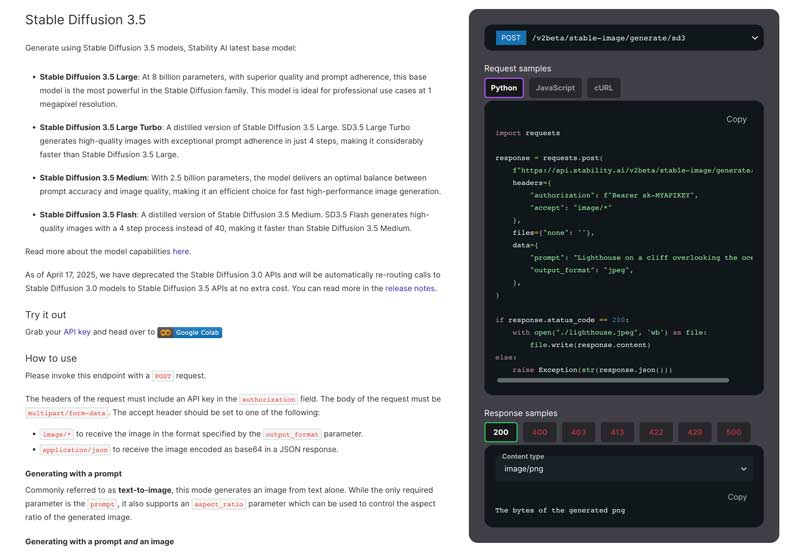
Für unterschiedliche technische Erfahrungsstufen stehen mehrere Ansätze zur Verfügung. Rufe die offizielle Website von Stability AI auf, hole dir eine Lizenz und sende dann wie gefordert eine POST-Anfrage.
Dank verschiedener integrierter Lösungen wurde der Einrichtungsprozess von Stable Diffusion erheblich vereinfacht. Darüber hinaus verfügt Stable Diffusion über eine Web-Benutzeroberfläche mit einem umfassenden Dashboard zur besseren Steuerung des Generierungsprozesses. Für eine effektive lokale Bereitstellung empfiehlt es sich außerdem, die empfohlenen Hardwareanforderungen zu überprüfen. Für Anfänger empfehlen wir die Verwendung von Stable Diffusion unter Windows 10 oder 11.
Die meisten aktiven Communities und Plattformen wie Reddit, Discord und Foren sammeln verwandte Techniken, Kreationen und Problemlösungen zum Thema Stable Diffusion. Dieses Community-basierte Support-Ökosystem kann schnell neue Modelle, Funktionen, praktische Workarounds und andere wertvolle Ressourcen teilen.
| Funktion/Modell | Stabile Diffusion | Mitten auf der Reise | Saattanz | VEO 3 |
| Preisgestaltung | Kostenloses Open-Source-Modell (Community-Lizenz). Kosten für Hardware und Cloud | Abonnement: Etwa $10 – $$1.152/Monat | API: $0.09 – $1.50 pro Video | API: Preise für die Gemini Developer API |
| Hardwareanforderungen | Hoch (erfordert eine leistungsstarke GPU) | Niedrig (läuft auf Discord, keine lokale Hardware erforderlich) | Cloudbasiert (keine Benutzerhardware erforderlich) | Cloudbasiert (keine Benutzerhardware erforderlich) |
| Anpassung | Umfangreich (Open Source, unterstützt ControlNet, LoRA und benutzerdefiniertes Modelltraining) | Eingeschränkt (durch Eingabeaufforderungen und grundlegende Parameter) | Umfangreich (durch Eingabeaufforderungen und kreative Kontrollen) | Begrenzt (hauptsächlich in Eingabeaufforderungen) |
| Bild-/Videoqualität | Hohe Obergrenze, abhängig von Modellen und Tuning | Hohe Standardqualität, starker künstlerischer Stil | Hochauflösende 1080p-Videos | 8-sekündige 720p- bis 1080p-Videos |
| Textverständnis | Gut, mit benutzerdefinierten Modellen trainiert und verbessert werden | Exzellent | Ausgezeichnet, versteht komplexe Eingabeaufforderungen | Ausgezeichnet, versteht komplexe Erzählungen |
| Benutzerfreundlichkeit | Steilere Lernkurve | Leicht | API-basiert, erfordert Integration | Einfach, erfordert Integration |
Stable Diffusion eignet sich gut für bestimmte Benutzergruppen, insbesondere für solche mit technischen Kenntnissen und Anpassungsbedarf. Die Funktionen rechtfertigen den höheren Lernaufwand und die höheren Hardwareanforderungen. Für Einsteiger bieten viele Konkurrenten jedoch eine deutlich einfachere Einrichtung und Bedienung. Mit kompatibler Hardware und ausreichend Lernmotivation ist Stable Diffusion ein flexibles und kreatives Tool für die KI-Bildgenerierung.
Frage 1. Wie viel kostet Stable Diffusion?
Stability AI bietet eine Community License für Entwickler, Forscher, kleine Unternehmen und Kreative an, um die Core Models (einschließlich Stable Diffusion 3) kostenlos zu nutzen, es sei denn, dein Unternehmen erzielt mehr als 1 Mio. USD Jahresumsatz oder du nutzt die Stable-Diffusion-Modelle für einen kommerziellen Zweck. Im Allgemeinen sind die Core Models und abgeleiteten Werke für dich kostenlos nutzbar. Du gibst die erforderlichen Informationen ein und sendest dann eine Anfrage für die kostenlose Community License. Lies diesen Artikel, um weitere kostenlose KI-Bilderzeuger zu entdecken!
Frage 2. Gibt es Hardwareanforderungen für Stable Diffusion?
Wenn Sie Stable Diffusion auf Ihrem Computer ausführen möchten, hängt das Benutzererlebnis stark von der Hardware ab, insbesondere von GPU, RAM und CPU. Sie sollten über eine NVIDIA-Grafikkarte verfügen. Die CUDA-Technologie von NVIDIA verfügt über fortschrittliche Beschleunigungstechnologie. Sie kann die kompatibelste Option für die Ausführung von Stable Diffusion sein. AMD-Grafikkarten werden aufgrund mangelnder Optimierung oft nicht empfohlen.
Frage 3. Ist Stable Diffusion ideal für Anfänger?
Der Einstieg in Stable Diffusion ist dank Ein-Klick-Installationspaketen und Cloud-Diensten deutlich einfacher geworden. Für Anfänger ist der Prozess jedoch immer noch mit einer Lernkurve verbunden, ganz zu schweigen davon, das volle Potenzial auszuschöpfen. Unabhängig davon, ob Sie sich für die lokale Installation oder den Cloud-Dienst entscheiden, können Sie nach der Ausführung von Stable Diffusion über eine Web-Benutzeroberfläche mit der Anwendung interagieren. Die Web-Benutzeroberfläche verfügt über eine visuelle Schnittstelle für Text-zu-Bild- und Bild-zu-Bild-Funktionen. Sie können diese zum Erstellen und Ändern von Bildern verwenden. Darüber hinaus müssen Sie häufig detaillierte Textbeschreibungen angeben, um die gewünschten Bilder zu erstellen. Die endgültige Qualität Ihres generierten Bildes hängt stark von Ihren Eingabeaufforderungen ab.
Frage 4. Welche Arten von Bildern kann Stable Diffusion erzeugen?
Stable Diffusion kann Bilder in einer großen Vielfalt von Typen erzeugen. Die meisten Kunststile werden unterstützt, darunter realistische Bilder, Anime, Ölgemälde, Aquarell und andere. Die Ausgaben werden in erster Linie durch das verwendete spezifische KI-Modell und die gegebenen Prompts bestimmt.
Zuerst musst du ein Checkpoint-Modell auswählen. Das Modell bestimmt den Kernstil des generierten Bildes, etwa ob es realistisch oder cartoonhaft sein wird. Du kannst entsprechende Modelle auf Community-Plattformen wie Hugging Face suchen und herunterladen. Anschließend verfeinerst du es mit kleineren Modellen.
Frage 5. Kann ich Stable Diffusion für kommerzielle Zwecke nutzen?
Ja, Sie können Stable Diffusion für kommerzielle Zwecke nutzen. Bitte überprüfen Sie jedoch die spezifischen Bedingungen der von Ihnen verwendeten Stable Diffusion-Version auf der offiziellen Website. Die Regeln können sich zwischen verschiedenen Modellversionen geändert haben. Stellen Sie außerdem sicher, dass Ihre geplante kommerzielle Nutzung nicht gegen die verbotenen Aktivitäten der Lizenz verstößt. Beachten Sie außerdem den möglicherweise fehlenden Urheberrechtsschutz für die von Ihnen erstellten Bilder.
Abschluss
Diese Stable-Diffusion-Review bietet dir eine detaillierte Einführung in das Text-zu-Bild-Generierungsmodell von Stability AI, insbesondere in das neueste Stable Diffusion 3.5-Modell. Durch die Review solltest du einen klaren Überblick über seine Fähigkeiten, Leistung, Stärken und Schwächen haben. Am Ende dieses Beitrags solltest du genau wissen, was Stable Diffusion für dich leisten kann und ob es deine Zeit wert ist.
Fanden Sie dies hilfreich?
477 Stimmen

Adobe AI Image Generator im Test: Übersicht und Vor- und Nachteile
KI
Bing AI Image Generator: Ein detaillierter Blick auf den Image Creator
KI
Ultimative Überprüfung der Funktionen von Craiyon, AI Image Generator
KI
Master DALL-E AI Image Generator: Revolutionieren Sie Ihre Visuals
KIAiseesoft AI Photo Editor ist eine erweiterte Desktop-Anwendung zum Verbessern, Hochskalieren und Ausschneiden von Bildern.


