Sorotan: Obrolan AI , game seperti Retro , pengubah lokasi , Roblox yang tidak diblokir
Sorotan: Obrolan AI , game seperti Retro , pengubah lokasi , Roblox yang tidak diblokir
Bosan dengan alat gambar AI yang tak ada habisnya?
Stable Diffusion memposisikan dirinya sebagai solusi “kebebasan” untuk pembuatan gambar AI. Saat Anda mencari model teks-ke-gambar yang kuat yang dapat menghasilkan gambar berkualitas tinggi berdasarkan deskripsi teks Anda, Anda mungkin akan mengaksesnya atau mendapatkan rekomendasi terkait.
Namun, dalam bidang yang berkembang pesat dengan model dan pesaing serupa seperti Midjourney, Seedance, dan Veo 3, Anda mungkin bertanya-tanya: Apakah Stable Diffusion sepadan dengan waktu Anda, atau apakah Stable Diffusion benar-benar memberikan hasil tingkat profesional?
Ulasan Stable Diffusion ini memberikan semua informasi yang diperlukan tentang model pembuatan gambar AI ini dan menjawab pertanyaan tersebut.

Daftar isi
Stable Diffusion adalah model teks-ke-gambar deep learning yang fleksibel yang dikembangkan oleh Stability AI. Model ini berbasis teknologi difusi (dirilis pada 2022) yang dapat mengubah deskripsi tekstual menjadi representasi visual. Model ini menggunakan encoder teks CLIP ViT-L/14 untuk menghasilkan gambar berkualitas tinggi sebagai respons terhadap prompt.
Dibandingkan dengan model difusi sebelumnya, Difusi Stabil 3.5 terbaru secara signifikan mengurangi kebutuhan memori. Difusi ini dirancang dengan inovasi arsitektur yang hebat dengan mengimplementasikan proses difusi dalam ruang laten. Model sebelumnya beroperasi langsung dalam ruang citra.
Berkat terobosan teknis dan sifat sumber terbukanya, Stable Diffusion segera menarik basis pengguna yang jauh lebih luas, termasuk pengembang, peneliti, kreator individu, dan pengguna perusahaan.
• Terus Meningkat dengan Pembaruan Versi. Sejak rilis awalnya, model pembuatan teks-ke-gambar ini telah mengalami evolusi yang signifikan. Versi utama meliputi Stable Diffusion 1.5, 2.0, 2.1, 3.0, dan seri terbaru 3.5. Versi-versi tersebut telah memberikan peningkatan besar dalam berbagai aspek, termasuk kualitas output, pemahaman prompt, dan kemampuan generasi, dan lain-lain.
• Banyak Versi Model. Beberapa model khusus dirancang untuk memenuhi berbagai kebutuhan pengguna. Model dasar terbaru adalah Stable Diffusion 3.5. Model ini menawarkan peningkatan signifikan dibandingkan versi sebelumnya. Saat ini ada empat versi utama dalam keluarga Stable Diffusion: Stable Diffusion 3.5 Large, Large Turbo, Medium, dan Flash.
• Pemahaman Prompt yang Canggih. Stable Diffusion 3.5 saat ini memiliki arsitektur multi-encoder teks yang canggih yang memungkinkannya memproses prompt yang lebih kompleks dan detail dengan lebih efektif. Model ini dapat memproses deskripsi teks hingga 10.000 karakter. Hal ini memungkinkan pengguna memberikan deskripsi yang lebih rinci. Sementara itu, Stable Diffusion dapat menghasilkan hasil yang lebih berkualitas tinggi dan lebih akurat.
• Fleksibilitas Komersial dan Kreatif. Model Stable Diffusion 3.5 dirilis di bawah Stability AI Community License dan Enterprise License. Lisensi ini mengizinkan penggunaan komersial maupun non-komersial. Untuk sebagian besar pengguna biasa, seperti peneliti, pengembang, dan usaha kecil dengan pendapatan tahunan kurang dari $1M, mereka dapat menggunakan Stable Diffusion secara bebas tanpa batasan. Pengguna dapat dengan bebas menyesuaikan AI dengan kebutuhan spesifik dan gaya artistik mereka.
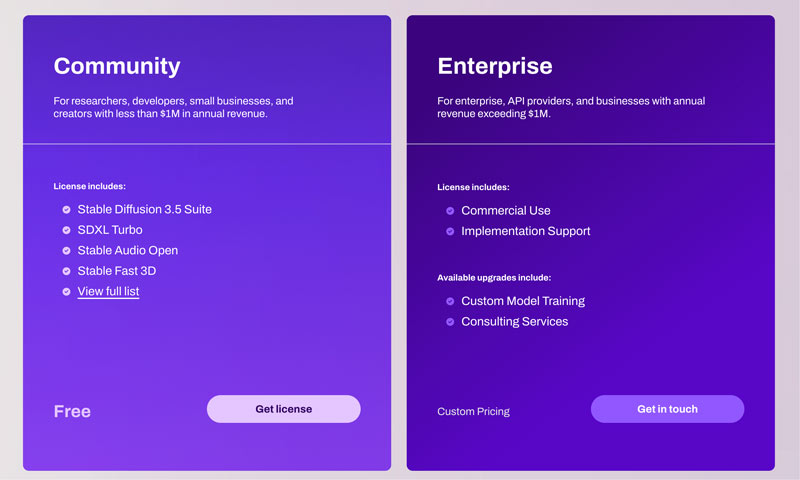
Sebagaimana disebutkan sebelumnya, fleksibilitas Stable Diffusion membuatnya cocok untuk hampir semua pengguna. Baik pengembang, peneliti, desainer, seniman digital, penggemar AI, bahkan mahasiswa dapat memperoleh manfaat signifikan dari kemampuannya.
Model Stable Diffusion 3.5 terbaru memiliki kemampuan canggih untuk menghasilkan detail gambar yang lebih halus. Foto yang dihasilkan seringkali memiliki pencahayaan dan subjek yang akurat. Selain itu, model ini dapat lebih sesuai dengan gaya seni spesifik berdasarkan permintaan Anda.
Untuk sebagian besar model pembangkitan gambar, area seperti tangan manusia dan fitur wajah bisa sangat menantang. Dengan penerapan VAE 16 kanal, artefak dan ketidaksempurnaan umum ini dapat diatasi secara efektif. Difusi Stabil sangat baik dalam menghasilkan efek pencahayaan yang akurat.
Meskipun ada peningkatan ini, Stable Diffusion masih memiliki kelemahan. Model ini masih menghadapi tantangan tertentu, terutama dalam rendering seluruh tubuh. Seperti model pembuatan gambar AI lainnya, Stable Diffusion seringkali menghasilkan hasil yang tidak terduga, terutama saat menghasilkan figur manusia utuh. Stable Diffusion 3.5 saat ini berkinerja baik dengan bidikan close-up, potret, dan berbagai subjek non-manusia.
Efisiensi Stable Diffusion bervariasi tergantung pada versi model yang digunakan, perangkat keras, pengaturan output, dan prompt. Umumnya, dengan GPU NVIDIA yang bertenaga, Anda dapat dengan mudah menghasilkan gambar standar 1024x1024 dalam 5-15 detik. Lebih baik daripada banyak alternatif lainnya, Stable Diffusion memungkinkan pengguna untuk melatih dan menyempurnakan model pada set data mereka sendiri. Hal ini sangat berharga bagi pengguna profesional.
Dibandingkan model-model sebelumnya, Stable Diffusion 3.5 saat ini jauh lebih mudah digunakan. Namun, "kemudahan" ini sangat bergantung pada keterampilan teknis, tingkat pengalaman, dan antarmuka yang Anda pilih.
Berbagai pendekatan tersedia untuk tingkat kenyamanan teknis yang berbeda. Buka situs web resmi Stability AI, dapatkan lisensi, lalu kirim permintaan POST sesuai ketentuan.
Secara relatif, berkat berbagai solusi terintegrasi, proses pengaturan Stable Diffusion telah disederhanakan secara drastis. Selain itu, Stable Diffusion memiliki WebUI yang menampilkan dasbor komprehensif untuk mengontrol proses pembuatan sistem dengan lebih baik. Untuk penerapan lokal yang efektif, disarankan juga untuk memverifikasi persyaratan perangkat keras yang disarankan. Untuk pemula, kami merekomendasikan penggunaan Stable Diffusion di Windows 10 atau 11.
Sebagian besar komunitas dan platform aktif, seperti Reddit, Discord, dan forum, mengumpulkan teknik, kreasi, dan solusi pemecahan masalah terkait Stable Diffusion. Ekosistem dukungan berbasis komunitas ini dapat dengan cepat berbagi model, fitur, solusi praktis, dan sumber daya berharga lainnya.
| Fitur/Model | Difusi Stabil | Tengah perjalanan | Benih | VEO 3 |
| harga | Model sumber terbuka gratis (Lisensi Komunitas). Biaya untuk perangkat keras dan cloud | Langganan: Sekitar $10 – $$1.152/bulan | API: $0.09 – $1.50 per video | API: Harga API Pengembang Gemini |
| Persyaratan Perangkat Keras | Tinggi (membutuhkan GPU yang kuat) | Rendah (berjalan di Discord, tidak memerlukan perangkat keras lokal) | Berbasis cloud (Tidak memerlukan perangkat keras pengguna) | Berbasis cloud (Tidak memerlukan perangkat keras pengguna) |
| Kustomisasi | Luas (Sumber terbuka, mendukung ControlNet, LoRA, dan pelatihan model khusus) | Terbatas (Melalui perintah dan parameter dasar) | Luas (melalui perintah dan kontrol kreatif) | Terbatas (Terutama dalam prompt) |
| Kualitas Gambar/Video | Batas atas tinggi, tergantung pada model dan penyetelan | Kualitas default tinggi, gaya artistik yang kuat | Video definisi tinggi 1080p | Video 720p hingga 1080p berdurasi 8 detik |
| Pemahaman Teks | Bagus, dilatih dan ditingkatkan dengan model khusus | Bagus sekali | Sangat baik, memahami perintah yang rumit | Sangat baik, memahami narasi yang kompleks |
| Kemudahan penggunaan | Kurva pembelajaran yang lebih curam | Mudah | Berbasis API, memerlukan integrasi | Mudah, perlu integrasi |
Stable Diffusion adalah pilihan yang baik untuk kelompok pengguna tertentu, terutama mereka yang memiliki keterampilan teknis dan kebutuhan kustomisasi. Stable Diffusion menawarkan kemampuan yang sesuai dengan kurva pembelajaran dan kebutuhan perangkat kerasnya yang lebih tinggi. Namun, bagi pemula, banyak pesaing menawarkan pengaturan dan pengalaman penggunaan yang jauh lebih mudah. Jika Anda memiliki perangkat keras yang kompatibel dan motivasi belajar yang cukup, Stable Diffusion adalah alat yang fleksibel dan kreatif untuk pembuatan gambar AI.
Pertanyaan 1. Berapa biaya penggunaan Stable Diffusion?
Stability AI menawarkan Community License bagi pengembang, peneliti, usaha kecil, dan kreator untuk menggunakan Core Models (termasuk Stable Diffusion 3) secara gratis, kecuali jika bisnis Anda menghasilkan pendapatan tahunan lebih dari USD $1M atau Anda menggunakan model Stable Diffusion untuk tujuan komersial. Secara umum, Core Models dan Derivative Works dapat Anda gunakan secara gratis. Anda hanya perlu mengisi informasi yang diperlukan lalu mengirim permintaan untuk Community License gratis. Baca artikel ini untuk mendapatkan lebih banyak generator gambar AI gratis!
Pertanyaan 2. Apakah ada persyaratan perangkat keras untuk Stable Diffusion?
Ketika Anda ingin menjalankan Stable Diffusion di komputer Anda, pengalaman pengguna sangat bergantung pada perangkat keras, terutama GPU, RAM, dan CPU. Anda harus memiliki kartu grafis NVIDIA. Teknologi CUDA NVIDIA dirancang dengan teknologi akselerasi canggih. Ini bisa menjadi pilihan yang paling kompatibel untuk menjalankan Stable Diffusion. Kartu grafis AMD seringkali tidak direkomendasikan karena kurangnya optimasi.
Pertanyaan 3. Apakah Stable Diffusion cocok untuk pemula?
Memulai Stable Diffusion kini jauh lebih mudah berkat paket instalasi sekali klik dan layanan cloud. Namun, bagi pemula, prosesnya masih membutuhkan proses pembelajaran, apalagi untuk menguasai potensi penuhnya. Baik Anda memilih instalasi lokal atau layanan cloud-nya, setelah menjalankan Stable Diffusion, Anda dapat berinteraksi dengannya melalui WebUI. Antarmuka Pengguna Web (WUI) memiliki antarmuka visual untuk fungsi teks-ke-gambar dan gambar-ke-gambar. Anda dapat menggunakannya untuk menghasilkan dan memodifikasi gambar. Selain itu, Anda sering kali perlu memberikan deskripsi teks yang detail untuk menghasilkan gambar yang diinginkan. Kualitas akhir gambar yang Anda hasilkan sangat bergantung pada perintah yang Anda berikan.
Pertanyaan 4. Jenis gambar apa saja yang dapat dihasilkan Stable Diffusion?
Stable Diffusion dapat menghasilkan gambar dalam berbagai jenis. Sebagian besar gaya seni didukung, termasuk gambar realistis, anime, lukisan minyak, cat air, dan lainnya. Output terutama ditentukan oleh model AI spesifik yang digunakan dan prompt yang diberikan.
Pertama, Anda perlu memilih model Checkpoint. Model ini menentukan gaya inti gambar yang dihasilkan, misalnya apakah akan tampak realistis atau kartun. Anda dapat mencari dan mengunduh model terkait dari platform komunitas, seperti Hugging Face. Lalu, sempurnakan dengan model-model yang lebih kecil.
Pertanyaan 5. Bisakah saya menggunakan Stable Diffusion untuk tujuan komersial?
Ya, Anda dapat menggunakan Stable Diffusion untuk tujuan komersial. Namun, harap periksa ketentuan khusus versi Stable Diffusion yang Anda gunakan di situs web resmi. Aturan mungkin telah berubah di berbagai versi model. Selain itu, Anda harus memastikan penggunaan komersial yang Anda rencanakan tidak melanggar aktivitas terlarang lisensi. Selain itu, waspadai potensi kurangnya perlindungan hak cipta untuk gambar yang Anda buat.
Kesimpulan
Ulasan Stable Diffusion ini memberi Anda pengenalan terperinci tentang model pembuatan gambar dari teks milik Stability AI, khususnya untuk model terbaru Stable Diffusion 3.5. Anda seharusnya sudah mendapatkan gambaran yang jelas tentang kemampuan, performa, kelebihan, dan kekurangannya melalui ulasan ini. Di akhir artikel ini, Anda seharusnya tahu dengan tepat apa yang dapat dilakukan Stable Diffusion untuk Anda dan apakah model ini layak untuk Anda gunakan.
Apakah Anda merasa ini membantu?
477 Suara

Ulasan Adobe AI Image Generator: Gambaran Umum, Kelebihan & Kekurangan
AI
Bing AI Image Generator: Tinjauan Mendalam tentang Pembuat Gambar
AI
Ulasan Utama Craiyon, Fitur Pembuat Gambar AI
AI
Master DALL-E AI Image Generator: Merevolusi Visual Anda
AIAiseesoft AI Photo Editor adalah aplikasi desktop canggih yang dirancang untuk menyempurnakan, menaikkan skala, dan memotong gambar.


