スポットライト:AIチャット、Retro風ゲーム、位置情報変更ツール、ブロック解除されたRoblox
AIの世界はもはや一強時代ではありません。OpenAIのChatGPTに加えて、人工知能の未来を再定義しようとする有力な競合モデルが他にも登場しています。その中でもGoogle Geminiは有力な候補として頭角を現しています。
しかし、有力な代替モデルがひしめくこの分野で、次のような疑問が浮かぶかもしれません。なぜGeminiなのか?なぜこのモデルは開発者、研究者、企業、一般ユーザーの注目を集めているのか?自分は使うべきなのか?
このGeminiレビューでは、このモデルの概要、性能、費用、誰に向いているのかなどを解説し、あなたのニーズに合ったAIかどうか判断するために必要な情報を提供します。

目次
GeminiはGoogle DeepMindによって開発されたAIアシスタントです。大規模言語モデル群の総称であり、マルチモーダルAIモデルでもあります。テキスト、画像、音声、さらには動画など、複数のモダリティにわたって情報を処理・生成できます。GeminiはGoogleの従来モデルであるLaMDAおよびAIチャットボットBardの後継にあたります。現在は検索やWorkspaceなど、Googleのエコシステム全体に統合されています。
Geminiの中核となる理念は「ネイティブなマルチモーダル性」です。多くのモデルはテキストしか処理できないことに気づくでしょう。他のモデルがテキスト用・画像用と別々に訓練されているのに対し、Geminiはマルチモーダルであることで、異なる種類の情報を同時に理解し、推論できます。テキスト、画像、コード、音声を一度に学習しているのです。
• ネイティブなマルチモーダル性はGeminiの代表的な機能です。テキスト、画像、音声、コードなど、さまざまなタイプの情報を処理・生成できます。
• Geminiは単一のモデルではなく、用途ごとに最適化されたモデル群を指します。たとえば、メールやコード、投稿や記事の作成、情報要約、テキストからの画像生成、アップロードした文書や写真の分析など、さまざまなタスクに対応できます。
• Google DeepMindによって開発されたGeminiは、複雑な推論やロジック、問題解決に優れています。さらに、他のGoogle製品との統合も深く、Gmail、ドキュメント、スプレッドシート、スライドなどから簡単に利用できます。
• Google Geminiは高度なコード生成機能を備えて設計されています。20以上の主要なプログラミング言語をサポートし、コードの解析、生成、リファクタリングが可能です。
1. Google Geminiの学習データセットはテキストだけではありません。前述のとおり、テキスト、画像、コード、音声など、数兆規模のデータポイントで訓練されています。これにより、モデルは概念を統一的な内部表現として扱うことができます。
2. Geminiは効率的なMixture-of-Experts(MoE)アーキテクチャで設計されています。これは、単一の巨大なネットワークではないということです。代わりに、多数の小さなネットワークから構成されています。MoEアーキテクチャによりGeminiは実行・処理が効率化され、入力ごとに一部の専門サブネットワークだけを起動します。従来型モデルのように、すべてのクエリでネットワーク全体を動かす必要がなく、その結果、複雑なタスクにおける性能が向上します。
3. Geminiは外部ツールやAPIとの連携に特化して最適化されています。他のソフトウェアと連携・やり取りできることで、あらゆるワークフローを処理する強力なエージェントとなります。
GeminiはAlphaGoやAlphaFoldを手がけたGoogle DeepMindによって開発されました。技術論文では、印象的なベンチマーク結果が示されています。GPT-4、Claude、DeepSeekといった他の先進的なAIモデルに匹敵する高い性能を発揮することが多いはずです。ただし、実際の使用環境でのパフォーマンスには注意が必要です。
GeminiはMMLUのようなベンチマークで90.01%というスコアを記録しており、これは57分野にまたがるテストです。理論上は、OpenAIのGPT-4よりも高い性能を示していることになります。
実際にも、このモデルは非常に優秀な言語モデルです。データ要約、文章作成、推論、翻訳、画像生成など、さまざまな一般タスクで優れています。多くの場合、Geminiはプロンプトに基づいて高品質な結果を生成できます。
一方で、時折ステレオタイプ的な回答を出すことがあります。また、一部の競合モデルと比べるとややフォーマルな口調です。一般的には、事実をでっちあげる傾向は少ないとされています。
コード生成はGeminiが最も得意とする分野のひとつです。HumanEvalのようなベンチマークでもトップクラスの成績を収めています。
Geminiは動作するコードを生成できるだけでなく、そのロジックの説明、デバッグ、必要なライブラリの提案も行えます。Go、Rust、Kotlinなどを含む20以上のプログラミング言語をサポートしています。
Geminiはネイティブなマルチモーダル性を備えて設計されており、画像やその他の情報形式を非常に深く解釈できます。複雑な画像でも容易に分析可能です。
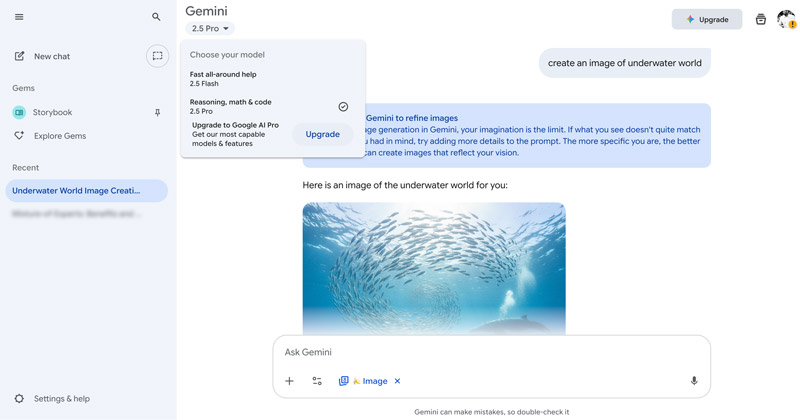
実環境でのテストでは、Geminiは画像内の主題やさまざまな物体を正確に認識できます。同様に、フローチャートやビジネス成長チャート、その他の図をアップロードした場合でも、データを分析し、詳細で正確な説明を返します。さらに、そのプロセスを解説したり、主要なデータトレンドを抽出することも可能です。
Geminiは幅広いタスクに利用されています。コンテンツクリエイターにとっては、投稿、記事、ストーリーなどの草案作成や執筆に非常に適しています。また、開発者にとっては、コードの生成やデバッグ、新しいプログラミング言語やフレームワークの学習を効率化する手段にもなります。
教育者や学生は、このモデルを使ってアイデアをブレインストーミングしたり、難解な論文を要約したり、長文コンテンツから主要データを抽出したりできます。ビジネスパーソンにとっては、メール返信、レポート作成、データ分析、市場動向の予測、会議メモの作成などに役立ちます。一般ユーザーにとっても、さまざまな質問への回答、旅行計画、希望するイラスト生成などに最適です。
GoogleのGemini、OpenAIのGPT-4、AnthropicのClaudeは、現在のAI三強と言える存在です。以下の表では、それらを簡潔に比較しています。
| 機能 | Google Gemini | OpenAI GPT-4 | Anthropic Claude 3 |
| 強み | ネイティブなマルチモーダル性と統合性 | オールラウンドなトップクラスの性能・エコシステム・推論力 | 安全性・コンテキストウィンドウ |
| マルチモーダル | ネイティブ | 複合型:分離されているが連携されたモデル GPT-4oはネイティブなマルチモーダル | 分離型:テキストと画像で別モデル |
| コード生成 | 高品質で深く統合されている | 優れた性能と巨大なエコシステム(GitHub Copilot) | 良好で、明確さを重視 |
| 推論 | 強力 | 非常に強力 | 優れている。特にニュアンスを伴う分析に強い |
| コンテキストウィンドウ | 特定のバージョンでは100万トークン | 128Kトークン | 200Kトークン、Opusは100万トークン |
| 主な差別化要因 | Googleエコシステムとの統合 | サードパーティ製アプリが豊富なエコシステム(ChatGPT) | 長文ドキュメント向けの大きなコンテキストウィンドウ |
Googleは段階的な料金体系を採用しており、Geminiモデルを多くのユーザーが利用しやすいようにしています。
Geminiには無料版(現在は2.5 Flash)があり、公式サイトで標準的なチャットボット体験を提供しています。Gemini Proモデルを基盤としており、無料で利用可能です。画像のアップロードや画像生成、ガイド付き学習、質問応答など、主要機能を試すことができます。問い合わせ回数には制限がありますが、一般ユーザーが基本的なタスクをこなすには十分です。
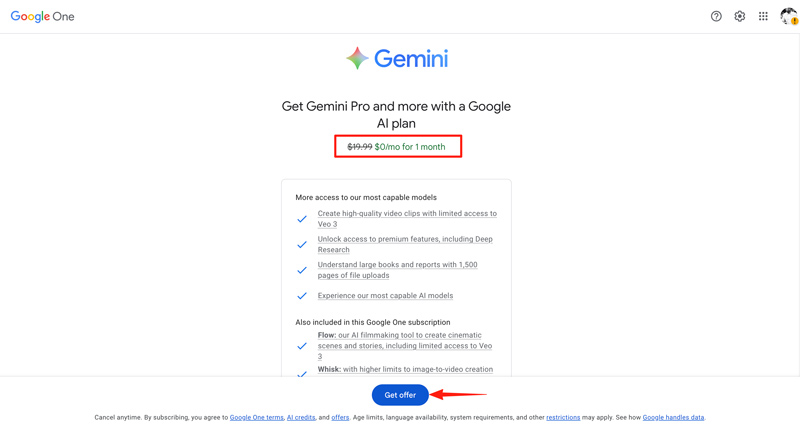
Gemini Proやさらに高度な機能は、Google AIプランで利用できます。このプランでは、Deep Researchのようなプレミアム機能へのアクセス、高品質な動画クリップの作成、最先端モデルの利用、拡張された能力、長い会話に対応する拡張コンテキスト、Google Oneサブスクリプションに含まれる2TBのクラウドストレージなど、複数の特典が提供されます。詳細はアップグレードボタンから確認できます。
企業向けには、Workspace専用のGeminiバージョンが提供されています。強化されたセキュリティ、高度な管理者コントロール、データガバナンス、専用サポートが含まれます。Gemini APIの料金はテキストの入出力に対して1文字単位で課金され、他の主要モデルと比べても競争力のある価格設定となっています。
はい、一度試してみる価値は十分にあります。Google Geminiは単なる別のモデルやチャットボットではなく、現代のAI分野における有力なプレーヤーです。
AIに少しでも興味があるなら、まずは無料のGeminiティアから始めるべきです。このモデルは、質問への回答、コンテンツ生成、コード作成を無料で行える強力なツールです。開発者、学生、あるいはGoogleサービスを日常的に利用しているプロフェッショナルであれば、ワークフローに組み込まない手はありません。利用方法については、包括的なGeminiの使い方チュートリアルが参考になります。
質問1.Geminiの潜在的な用途にはどのようなものがありますか?
多用途なAIプラットフォームとして、GoogleのGeminiには、一般的な会話からクリエイティブな画像編集、ビジネスソフトウェアとの統合まで、幅広い応用例があります。その核となる強みはマルチモーダル性です。テキスト、画像、音声、動画といった情報を理解し、処理できます。ソフトウェア開発では、Geminiはコード生成、デバッグ、アルゴリズムの説明などを支援します。多くのGemini機能には、Web上またはGeminiアプリから直接アクセス可能です。
質問2.Geminiは無料で使えますか?
はい、Geminiは無料で利用を始められます。無料版はライトユーザーや初めて利用する人に最適です。ただし、無料枠には会話回数や生成量などの制限があります。動画生成などの高度な機能にアクセスしたり、より高頻度でのやり取りを行ったり、制限を緩和したい場合は、Google AI Proサブスクリプションへのアップグレードが必要です。
公式サイトにアクセスするか、モバイルアプリをダウンロードすることで、Geminiを無料で使い始められます。無料プランでも、一般的な会話などの中核機能を一定範囲内で利用できます。
質問3.Geminiの制限事項は何ですか?
私たちのテスト、ユーザー体験、最近の報告に基づくと、GoogleのGemini AIにはいくつか顕著な制限があります。ChatGPTのような競合と比べると、コーディングと数学の能力が劣る場合があります。単純なタスクでも誤った情報を生成したり、有害な内容を出力する可能性があります。事実の正確性という点で、ユーザーはGeminiに全面的に依存すべきではありません。特に自分がよく知らないトピックについては、信頼できる情報源で重要な情報を検証する必要があります。さらに、ファイル削除の事例は重大なリスクを浮き彫りにしています。開発者や研究者であれば、GeminiのAPIを統合する際には徹底的なテストを行うべきです。
質問4.Geminiは動画を生成できますか?
はい、GoogleのGeminiはテキストから、あるいは画像とテキストプロンプトの組み合わせから動画を生成できます。この動画生成機能はVeo 3モデルによって実現されています。ただし、この高度な機能は有料サブスクリプション(Google AI ProまたはGoogle AI Ultra)にのみ提供されています。Geminiが現在生成できるのは8秒未満の短いクリップに限られ、さらにAI生成であることを示すウォーターマークが付く場合があります。これらの制約がニーズに合わない場合は、CyberLinkのDirector SuiteやMyEditなどの代替ツールが推奨されます。
結論
このGeminiレビューは、このAIアシスタントを理解するための決定版ガイドです。主要機能、推論およびコーディング能力、さまざまなタスクでのパフォーマンス、その長所と短所を知ることができます。また、GPT-4やClaudeといったライバルとの比較も行っています。Google Geminiがあなたのニーズに合ったAIかどうか迷っているなら、まずは無料トライアルから始めることをおすすめします。
役に立ちましたか?
477 票
Kuki AIチャットボットソフトウェアレビュー:本当に役立ち安全か
AI
Chai アプリ レビュー:AIチャットボットとの会話
AI
AI Chat & AI Writer「Genie」レビュー:執筆のインスピレーションを呼び覚ます
AI
Chatsonic最新レビュー:最高のChatGPT代替
AI

