スポットライト:AIチャット、Retro風ゲーム、位置情報変更ツール、ブロック解除されたRoblox
終わりのないAI画像ツール探しにうんざりしていませんか?
「Stable Diffusion」は、AI画像生成における“自由”なソリューションとして位置付けられています。高品質な画像をテキスト説明に基づいて生成できる強力なテキストから画像へのモデルを探すとき、Stable Diffusionにアクセスしたり、関連するおすすめとして目にすることがあるでしょう。
しかし、Midjourney、Seedance、Veo 3 などの類似モデルや競合がひしめく急速拡大中の分野において、「Stable Diffusion は時間をかける価値があるのか」「本当にプロレベルの成果を出せるのか」と疑問に思うかもしれません。
この「Stable Diffusion レビュー」では、このAI画像生成モデルに関する必要な情報をすべて提供し、その疑問に答えます。

目次
Stable Diffusion は、Stability AI によって開発された柔軟なディープラーニング型のテキストから画像へのモデルです。2022年に公開された拡散(ディフュージョン)技術に基づいており、テキストによる説明を視覚的な表現へと変換できます。このモデルは CLIP ViT-L/14 テキストエンコーダーを利用し、プロンプトに応じて高品質な画像を生成します。
従来の拡散モデルと比べて、最新の Stable Diffusion 3.5 はメモリ要件を大幅に削減しています。拡散プロセスを潜在空間上で実装するという優れたアーキテクチャ上の革新により設計されており、それ以前のモデルが直接画像空間で動作していたのとは対照的です。
この技術的ブレイクスルーとオープンソース性のおかげで、Stable Diffusion は、開発者、研究者、個人クリエイター、エンタープライズユーザーなど、はるかに広いユーザーベースを急速に獲得しました。
・バージョンアップによる継続的な進化。初期リリース以降、このテキストから画像への生成モデルは大きな進化を遂げてきました。主なバージョンには Stable Diffusion 1.5、2.0、2.1、3.0、そして最新の 3.5 シリーズが含まれます。出力品質、プロンプト理解、生成能力など、さまざまな側面で大幅な改良が行われています。
・複数のモデルバージョン。異なるユーザーのニーズに対応するため、いくつかの専用モデルが用意されています。最新のベースモデルは Stable Diffusion 3.5 で、以前のバージョンに比べて大きな改善が施されています。現在、Stable Diffusion ファミリーには主に 4 つのバージョンがあり、Stable Diffusion 3.5 Large、Large Turbo、Medium、Flash が提供されています。
・高度なプロンプト理解。現行の Stable Diffusion 3.5 は高度なマルチテキストエンコーダーアーキテクチャを採用しており、より複雑で詳細なプロンプトを効果的に処理できます。最長 10,000 文字までのテキスト説明を扱うことができ、ユーザーはより綿密な説明を与えられます。その結果、Stable Diffusion はより高品質で正確な結果を生成できます。
・商用利用とクリエイティブな柔軟性。Stable Diffusion 3.5 モデルは Stability AI Community License および Enterprise License の下で提供されており、商用・非商用の両方の利用が許可されています。研究者、開発者、年間売上 $1M 未満の小規模ビジネスなど、多くの一般的なユーザーは、Stable Diffusion を制限なく無料で利用できます。ユーザーは自分のニーズやアートスタイルに合わせてこのAIを自由にカスタマイズできます。
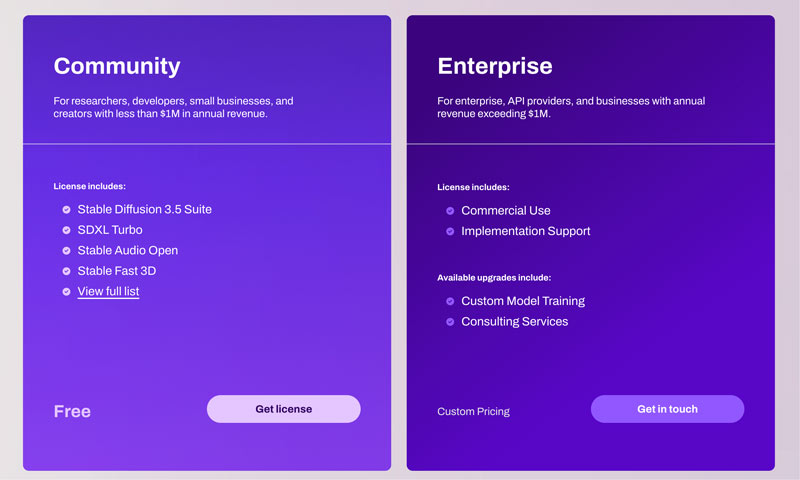
前述のように、Stable Diffusion の汎用性により、ほとんどすべてのユーザーに適しています。開発者、研究者、デザイナー、デジタルアーティスト、AI愛好家、さらには学生まで、その機能から大きな恩恵を受けることができます。
最新の Stable Diffusion 3.5 モデルは、より細かな画像ディテールを生成できる高度な能力を備えています。生成された画像は、ライティングや被写体の表現が正確であることが多く、さらに、プロンプトに基づいて特定のアートスタイルをよりうまく反映できます。
多くの画像生成モデルにとって、人間の手や顔の特徴といった領域は特に難しいポイントです。Stable Diffusion では 16 チャンネル VAE を採用することで、こうした一般的なアーティファクトや破綻を効果的に軽減しています。Stable Diffusion は正確なライティング効果のレンダリングが得意です。
これらの改善にもかかわらず、Stable Diffusion にも弱点は残っています。特に全身描写においてはいくつかの課題を抱え続けています。他のAI画像生成モデルと同様に、Stable Diffusion も、人物の全身を生成するときに予期しない結果を出すことが少なくありません。現行の Stable Diffusion 3.5 は、クローズアップやポートレート、非人間の被写体に関しては良好なパフォーマンスを発揮します。
Stable Diffusion の効率は、使用するモデルバージョン、ハードウェア、出力設定、プロンプトなどによって異なります。一般的に、十分な性能の NVIDIA GPU があれば、標準的な 1024×1024 画像を 5~15 秒程度で容易に生成できます。多くの代替モデルと比べて優れている点として、Stable Diffusion はユーザー自身のデータセットでモデルをトレーニングしたり微調整したりできることが挙げられます。これはプロフェッショナルユーザーにとって特に価値があります。
従来モデルと比較すると、現行の Stable Diffusion 3.5 ははるかに扱いやすくなっています。ただし、「簡単」と感じるかどうかは、技術スキルや経験レベル、利用するインターフェースによって大きく変わります。
技術レベルに応じて複数のアプローチが用意されています。公式の Stability AI サイトにアクセスし、ライセンスを取得して、指定どおりに POST リクエストを送信します。
相対的に見て、さまざまな統合ソリューションのおかげで Stable Diffusion のセットアッププロセスは大幅に簡素化されました。さらに、Stable Diffusion には、生成プロセスをより細かく制御できる包括的なダッシュボードを備えた WebUI があります。ローカル環境に効率的に導入するには、推奨ハードウェア要件を確認しておくことも重要です。初心者には、Windows 10 または 11 上で Stable Diffusion を利用することを推奨します。
Reddit、Discord、各種フォーラムなど多くのアクティブなコミュニティやプラットフォームでは、Stable Diffusion に関するテクニック、作品、トラブルシューティングの情報が共有されています。このコミュニティ主導のサポートエコシステムによって、新しいモデルや機能、実用的な回避策やその他の有用なリソースが迅速に共有されます。
| 機能/モデル | Stable Diffusion | Midjourney | Seedance | VEO 3 |
| 価格 | 無料・オープンソースモデル(コミュニティライセンス)。ハードウェアおよびクラウド利用のコストが必要 | サブスクリプション:月額約 10~1,152(目安) | API:動画1本あたり約 0.09 ~ 1.50 | API:Gemini Developer APIの料金体系に準拠 |
| ハードウェア要件 | 高い(高性能GPUが必要) | 低い(Discord上で動作し、ローカルハードウェアは不要) | クラウドベース(ユーザー側ハードウェア不要) | クラウドベース(ユーザー側ハードウェア不要) |
| カスタマイズ性 | 高い(オープンソースで、ControlNet・LoRA・カスタムモデル学習に対応) | 限定的(プロンプトと基本パラメータによる) | 高い(プロンプトとクリエイティブコントロールによる) | 限定的(主にプロンプト内での調整) |
| 画像/動画品質 | 上限は高いが、モデルとチューニングに依存 | 初期品質が高く、芸術的スタイルに優れる | 高精細な1080p動画 | 8秒間の720p~1080p動画 |
| テキスト理解 | 良好。カスタムモデルで学習・強化が可能 | 優れている | 優秀。複雑なプロンプトも理解 | 優秀。複雑なストーリーも理解 |
| 使いやすさ | より急な学習曲線 | 簡単 | APIベースで、システムへの組み込みが必要 | 容易だが、統合作業が必要 |
Stable Diffusion は、主に技術スキルがありカスタマイズを重視する特定のユーザー層にとって良い選択肢です。学習コストやハードウェア要件がやや高いことを補って余りある機能を提供します。しかし、初心者にとっては、より簡単にセットアップして利用できる競合モデルも多数存在します。対応するハードウェアを用意でき、学習へのモチベーションが十分にあるなら、Stable Diffusion はAI画像生成のための柔軟で創造的なツールとなるでしょう。
質問1. Stable Diffusion の料金はいくらですか?
Stability AI は、開発者、研究者、小規模ビジネス、クリエイター向けに、Core Models(Stable Diffusion 3 を含む)を無料で利用できる コミュニティライセンス を提供しています。ただし、事業の年間売上が米ドル $1M を超えている場合や、Stable Diffusion モデルを商業目的で利用している場合は除きます。一般的に、Core Models とそれに基づく二次的著作物は無料で利用できます。必要事項を入力して申請を送信することで、無料のコミュニティライセンスを取得できます。さらに詳しい情報については、この記事から他の無料AI画像ジェネレーターをチェックしてください。
質問2. Stable Diffusion にハードウェア要件はありますか?
PC 上で Stable Diffusion を実行したい場合、ユーザー体験はハードウェア、特に GPU、RAM、CPU に大きく左右されます。NVIDIA 製グラフィックスカードを用意するべきです。NVIDIA の CUDA 技術は高度なアクセラレーション機能を備えており、Stable Diffusion を動かすうえで最も互換性の高い選択肢になり得ます。AMD 製グラフィックスカードは最適化が不足しているため、推奨されないことが多いです。
質問3. Stable Diffusion は初心者に向いていますか?
ワンクリックインストーラーやクラウドサービスのおかげで、Stable Diffusion を使い始めることは以前よりかなり簡単になりました。ただし、初心者にとっては、基本的なセットアップであっても一定の学習コストが伴い、その潜在能力を引き出すとなると尚更です。ローカルインストールを選ぶにせよクラウドサービスを利用するにせよ、Stable Diffusion を起動した後は WebUI を通じて操作します。Webユーザーインターフェースには、テキストから画像への変換や画像から画像への変換のための視覚的なインターフェースが備わっており、画像を生成・編集できます。また、望む画像を得るためには、詳細なテキストプロンプトを与える必要があることが多いです。生成画像の最終的な品質は、提供するプロンプトに大きく依存します。
質問4. Stable Diffusion はどのような種類の画像を生成できますか?
Stable Diffusion は、非常に幅広い種類の画像を生成できます。リアルな写真風、アニメ調、油絵、水彩画など、ほとんどのアートスタイルに対応しています。出力は主に、使用する特定のAIモデルと与えるプロンプトによって決まります。
まず、チェックポイントモデルを選択する必要があります。このモデルが、生成される画像のコアとなるスタイル(写実的か、カートゥーン調かなど)を決定します。Hugging Face などのコミュニティプラットフォームで関連モデルを検索・ダウンロードできます。そのうえで、小さなモデルを組み合わせてスタイルを細かく調整します。
質問5. Stable Diffusion を商用利用できますか?
はい、Stable Diffusion は商用利用が可能です。ただし、使用している Stable Diffusion のバージョンごとに公式サイトで定められた利用規約を必ず確認してください。ルールはモデルバージョンによって変更されている可能性があります。また、予定している商用利用がライセンスで禁止されている行為に該当しないことも確認すべきです。加えて、生成した画像には著作権保護が適用されない可能性がある点にも注意してください。
結論
この「Stable Diffusion レビュー」では、Stability AI のテキストから画像への生成モデル、特に最新の Stable Diffusion 3.5 モデルについて詳しく紹介しました。本レビューを通じて、その機能、パフォーマンス、長所・短所を明確に把握できたはずです。記事を読み終える頃には、Stable Diffusion が自分に何をもたらしてくれるのか、時間をかける価値があるのかを具体的に判断できるでしょう。
役に立ちましたか?
477 票

Adobe AI画像ジェネレーター レビュー:概要と長所・短所
AI
Bing AI画像ジェネレーター:Image Creatorの徹底解説
AI
Craiyon 最終レビュー:AI画像ジェネレーターの機能総まとめ
AI
DALL·E AI画像生成ツールを使いこなす:ビジュアル表現を革新しよう
AI

