Em destaque: bate-papo com IA , jogos como Retro , trocador de localização , Roblox desbloqueado
Em destaque: bate-papo com IA , jogos como Retro , trocador de localização , Roblox desbloqueado
Desde o lançamento inovador do Llama 1, as APIs proprietárias e fechadas foram irrevogavelmente democratizadas. A série Llama (Large Language Model Meta AI) de código aberto da Meta remodelou o cenário da IA. O altamente capaz Llama 3 e seu lançamento mais recente, Llama 4, fazem desta família de modelos a base para a inovação em IA de código aberto.
If you are confused by countless AI models, read this comprehensive Llama review. You can learn what Llama is, what makes Llama AI unique, its compelling business case, the competitive standing against giants like ChatGPT, a practical guide for enterprises, and more.

Índice
Llama refers to a collection of foundational large language models developed by Meta. Unlike previous models that can only be accessed via API, the Llama series is released publicly for research and commercial use. Indeed, a custom license is designed to prevent misuse, and it applies under specific scaling conditions. The latest version is Llama 4.
Llama 4 is the latest version. Meta claims that it is the most intelligent, scalable, and convenient version. With more advanced reasoning and planning abilities, multimodal capabilities, and multilingual writing functions, Llama 4 can be the industry-leading context window. It allows you to easily deploy your most incredible ideas with the Llama API and the Llama Stack. The current Llama 4 allows more personalized experiences.

Llama 3 was released in April 2024. Compared to Llama 2, Llama 3 has several improvements, including enhanced reasoning and coding, improved training data, a larger context window, and a more efficient tokenizer.
Llama 1 & 2: The original Llama was released in early 2023, and Llama 2 was released in July 2023. They marked Meta’s direct entry into the chatbot arena. With a fine-tuned variant, since Llama 2, the series delivers a helpful and safe dialogue. Llama 1/2 is mainly developed for challenging OpenAI’s ChatGPT and Google’s Bard head-on.
Developed by Meta for reshaping the AI landscape, the high performance won’t be your concern. Llama is fine-tuned on your company’s specific data to outperform larger generic models for specific tasks. The potential for fine-tuning nature makes it suitable for most developers and researchers.
Llama’s uniqueness is not just its performance. The ecosystem Llama has spawned can be a greater advantage. Its Hugging Face ecosystem has sparked an explosion of innovation. Thousands of fine-tuned derivatives are offered for different conceivable tasks.
Moreover, Llama has put a top-tier LLM into everyone’s hands. The democratization of AI is another benefit that makes Llama unique. Llama AI models are available for all researchers, developers, and startups to use, innovate, and build without paying API fees or asking for permission.
Strategic advantage for businesses. Llama lets your AI building be owned by yourself. You don’t need to tie to a vendor’s pricing, policy changes, or API deprecations anymore. That avoids vendor lock-in effectively.
O argumento de negócios da Llama não se resume apenas à utilização de um modelo de IA diferente. Na verdade, pode representar uma mudança fundamental na forma como uma empresa trata a IA.
In the early days, many businesses adopted API-based services, such as OpenAI’s GPT-4. That can be the most convenient option, allowing for low-barrier experimentation and rapid prototyping. However, this AI strategy has been replaced by a more strategic, long-term approach, open-source foundation models like Meta’s Llama.The Llama case rests on three key factors: cost savings, control and customization, and data security.
Os custos de API para muitas empresas (processando milhões de consultas por dia) podem chegar a milhões anualmente. A implantação do Llama representa uma mudança de despesa operacional (OpEx) para despesa de capital (CapEx). Isso torna o ROI claro em alto volume.
O Llama permite que você crie uma IA exclusiva e ajustada que melhor se adapta ao seu negócio ou produtos. Você também tem controle total sobre as entradas e saídas do seu modelo. Ele se torna um recurso essencial, não um serviço alugado.
Governos e finanças têm requisitos rigorosos de governança de dados. O Llama pode ser implantado totalmente no local ou em uma VPC (Nuvem Privada Virtual) compatível. Essa costuma ser a única maneira legal de aproveitar a tecnologia LLM. Além disso, implantar o Llama em uma VPC segura significa que todos os seus dados estão protegidos e nunca saem do seu firewall. Isso elimina efetivamente o risco de exposição de dados de terceiros.
In a word, the business case for Llama is about ownership. You are given back the ownership of your competitive advantage, the security of your data, and your costs.
Meta’s Llama provides a new way for businesses to use AI. This powerful AI model has a wide range of applications, including conversational AI, image and text generation, language training, summarization, and other related tasks. By using advanced AI capabilities, Llama can help businesses drive success.
• Customer Service & Support
Chatbots avançados ou assistentes virtuais com tecnologia Llama podem entender melhor as dúvidas dos clientes, especialmente as mais complexas, e fornecer respostas corretas e contextualizadas. Oferecer suporte ao cliente 24 horas por dia, 7 dias por semana, é vantajoso.
• Data Analysis & Business Intelligence
O Llama pode extrair dados de diversas fontes e tomar decisões que inicialmente exigiam habilidades técnicas. Ele permite que gerentes de negócios e analistas obtenham uma consulta SQL por meio de perguntas. O modelo pode analisar textos, imagens, gráficos e outros conteúdos para gerar um resumo narrativo. Isso ajuda a identificar rapidamente tendências emergentes, insights competitivos e reclamações comuns.
• Marketing & Content Automation
O processo de produção de conteúdo de alta qualidade e otimizado para SEO é demorado. O Llama pode gerar rapidamente rascunhos ou artigos inteiros com um tópico simples e diversas palavras-chave. Editores humanos podem então refinar esses resultados. O modelo também pode automatizar a criação de postagens em mídias sociais. Além disso, pode ajudar a escrever linhas de assunto atraentes para e-mails e anúncios.
• Software Development
Um modelo Llama específico para código pode atuar como um autocompletar avançado para manter a qualidade do código, gerenciar sistemas legados e acelerar os ciclos de desenvolvimento. Ele pode ajudar a revisar o código em busca de possíveis bugs. Além disso, pode gerar e atualizar automaticamente a documentação do código e as referências de API com base nos comentários do código-fonte.
Esta seção apresenta uma comparação lado a lado da série Llama da Meta com outras alternativas líderes em formato de tabela. Você pode comparar esses fatores-chave para encontrar a opção mais adequada às suas necessidades específicas.
Deve ficar claro que esses modelos de IA têm seus próprios pontos fortes e fracos. A escolha não se resume a encontrar uma única opção.
| Modelos de IA | LLaMA 4/3/2 da Meta | GPT-4 da OpenAI | Claude 3 da Anthropic | PaLM 2 do Google |
| Licença | Licença personalizada de código aberto | Proprietário | Proprietário | Proprietário |
| Acesso | Baixe e hospede-se | Somente API Acesso via assinatura | Somente API Acesso por meio de preços baseados no uso | Somente API Acesso via Vertex AI do Google |
| Modelos de IA | LLaMA 4/3/2 da Meta | GPT-4 da OpenAI | Claude 3 da Anthropic | PaLM 2 do Google |
| Desempenho | Nível superior Competitivo com os principais modelos de IA. Requer ajustes finos para corresponder ao desempenho do GPT-4 em tarefas específicas. É insuficiente para fornecer conteúdo criativo envolvente e de alta qualidade. | Líder da indústria Lidar com raciocínio complexo, nuances e resolução criativa de problemas | Nível superior Excelente em análise de dados, diálogo sofisticado e raciocínio de longo contexto | Nível superior Excelente em raciocínio e tarefas multilíngues |
| Estrutura de custos | Alto CapEx, Baixo OpEx Escalas de custo com tamanho do modelo e volume de uso | Sem CapEx, Alto OpEx Não custo inicial, mas pagamento por token para uso | Sem CapEx, alto OpEx Semelhante ao OpenAI, pagamento por token | Sem CapEx, alto OpEx Pagamento por token na Vertex AI, com descontos por volume |
| Privacidade e segurança de dados | Controle máximo Os dados nunca sairão da sua infraestrutura Ideal para indústrias altamente regulamentadas | Os dados de entrada/saída são processados nos servidores da OpenAI | Política de privacidade forte, mas os dados são processados pela Anthropic | Segurança de nível empresarial Dados processados no Google Cloud Oferece controles de VPC e compromissos de residência de dados |
| Personalização e Controle | Controle total Pode ser totalmente ajustado em dados proprietários | Limitado O ajuste fino está disponível apenas para modelos mais antigos (não GPT-4) | Limitado Personalizado por meio de engenharia rápida e contexto | Forte Bom suporte para ajuste fino e aprendizagem por reforço |
| Escalabilidade | Você precisa provisionar e gerenciar sua própria infraestrutura | O OpenAI gerencia toda a infraestrutura | A Anthropic gerencia toda a infraestrutura | O Google Cloud gerencia a infraestrutura |
Em geral, o Llama é ideal para empresas que preferem controle total, privacidade de dados e personalização. O GPT-4 é mais adequado para empresas que exigem o mais alto desempenho bruto e capacidade de raciocínio. Ele lida melhor com tarefas complexas, especialmente análises criativas e avançadas. O Claude 3 é ideal para aplicações onde a segurança e a redução de viés são primordiais. Raramente produz resultados prejudiciais. O PaLM 2 é ideal para empresas profundamente integradas ao ecossistema do Google Cloud. Ele garante uma integração perfeita com outras ferramentas do Google.
Antes de implantar o Llama, você deve primeiro definir suas necessidades de acordo com o caso de uso específico. Você precisa do modelo de parâmetros 70B para qualidade máxima ou apenas do modelo 8B para tarefas básicas?
Você deve escolher seu método de implantação, como uma máquina local, uma VM na nuvem ou um serviço gerenciado. Executar modelos Llama com eficiência geralmente requer uma GPU potente, especialmente para os modelos maiores. Depois disso, você pode baixar o modelo correto no site do Meta.
Click the Download Models button to enter the Request Access page. Provide the required information and choose a desired Llama model.
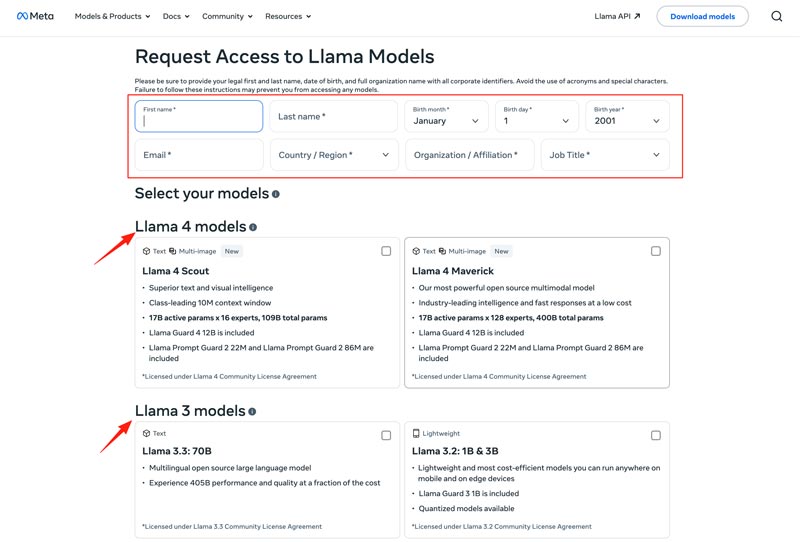
Click the Next button to read Terms and Conditions. You should check the Community License Agreement carefully and then click the Accept and Continue button. Follow the on-screen instructions to download your selected model.

You can use a framework like Text Generation Inference to get a high-performance API server. If you need a chat interface, deploy a UI like Chatbot UI or NextChat. After that, use your proprietary data with frameworks to create your own specialized model.
Você deve saber como superar desafios para usar modelos de IA de forma eficaz.
• Initial Setup Complexity
Você pode usar suas ferramentas e contêineres pré-construídos. Execute modelos localmente com um único comando. Você também pode recorrer a plataformas baseadas em nuvem sem nenhuma configuração local. O Hugging Face permite executar e criar demonstrações usando ambientes pré-configurados. Além disso, você pode começar com llama.cpp para executar uma versão quantizada do Llama.
• Resource Management & Cost Optimization
Modelos grandes exigem GPUs com muita memória, que geralmente são escassas e caras.
A quantização é a técnica mais eficaz. Você pode usar bibliotecas para quantização de 4 bits durante inferências ou ajustes finos. Em hardwares menos potentes, use llama.cpp para executar modelos. Ambos os métodos podem reduzir efetivamente o uso de memória. Além disso, certifique-se de selecionar o modelo correto para suas tarefas. Um modelo menor e com ajuste fino pode ser mais econômico.
• Staying Up-to-Date with New Releases
Muitos novos modelos, técnicas e bibliotecas são lançados semanalmente. Pode ser difícil se manter atualizado.
Você deve assinar os blogs oficiais, como Meta AI, Hugging Face e vLLM. Além disso, novas técnicas de ajuste fino, aplicações, ganhos de eficiência, experiências, soluções e muito mais são compartilhados em plataformas como GitHub e Hugging Face. Isso permite que sua equipe integre melhorias.
You May Also Need:
Question 1. Is it permitted to use the output of the Llama models to train other LLMs?
Sim, o Meta permite o uso de versões mais recentes (Llama 3.1 e posteriores) da saída do Llama para treinar outros modelos. Certamente, você não tem permissão para usá-lo para criar um produto que concorra com o Meta. Além disso, você deve estar ciente dos limites legais estabelecidos pela licença do Meta.
Question 2. Do Llama models have restrictions? What are the related terms?
Sim, os modelos Llama têm restrições significativas, definidas por sua estrutura de licenciamento. Esses modelos não são verdadeiramente de código aberto. Em vez disso, são lançados sob uma licença proprietária da Meta. Isso visa proteger os interesses da Meta e evitar casos de uso competitivos.
Question 3. What are the common use cases of Llama?
Os casos de uso diário do Llama incluem compreensão de imagens e documentos, resposta a perguntas, geração de imagens e textos, geração e sumarização de idiomas, treinamento de idiomas, IA de conversação e muito mais. O Llama pode responder à sua pergunta com base no conteúdo da imagem ou do documento fornecido. Além disso, ele pode ser usado para criar um chatbot ou um assistente visual.
Question 4. What are the hardware requirements for using Llama models?
Os requisitos de hardware para executar modelos Llama são determinados por três fatores principais: tamanho do modelo, quantização e caso de uso. Para a maioria dos desenvolvedores, uma RTX 4070/4080/4090 ou um Mac com 16-36 GB de memória unificada é uma escolha flexível para modelos Llama de até 70 GB. Para operação baseada em GPU, o fator mais crucial é a VRAM da sua placa de vídeo. Como mencionado, selecione o tamanho de modelo correto com base nas suas necessidades e, em seguida, escolha o nível de quantização que pode ser executado no seu hardware.
Question 5. Is Llama as good as ChatGPT?
You can check the table above to compare their key factors between Llama and ChatGPT. Llama can be run locally and offline. It offers more secure data protection. Moreover, the Llama model itself is free to use. ChatGPT has a free version, but its advanced models and features require a paid plan.
Conclusão
Llama is not just another model. It is often viewed as a strategic shift toward a more accessible and customizable AI future. You can learn various related information about the Llama AI family in this no-nonsense review and then find out if it is worth the hype.
Você achou isso útil?
484 Votes

Análise online dos 9 principais AI Chatbots: recursos, preços, prós e contras
IA
Revisão do Character.AI: liberando a criatividade no mundo da IA
IA
Revisão detalhada do YouChat: uma ferramenta de IA incrível para todos
IA
Os 7 melhores chatbots AI: geração instantânea de ideias
IA
