Spotlight: AI chat, games like Retro, location changer, Roblox unblocked
Spotlight: AI chat, games like Retro, location changer, Roblox unblocked
Tired of endless AI image tools?
Stable Diffusion positions itself as a “freedom” solution for AI image generation. When you search for a powerful text-to-image model that can generate high-quality images conditioned on your text descriptions, you may access it or get related recommendations.
However, in a rapidly expanding field with similar models and competitors like Midjourney, Seedance, and Veo 3, you may wonder: Is Stable Diffusion worth your time, or does Stable Diffusion truly deliver professional-grade results?
This Stable Diffusion review provides all the necessary information about this AI image generation model and answers that very question.

Table of contents
Stable Diffusion is a flexible deep learning, text-to-image model developed by Stability AI. It is based on diffusion technology (released in 2022) that can transform textual descriptions into visual representations. The model utilizes a CLIP ViT-L/14 text encoder to generate high-quality images in response to prompts.
Compared to earlier diffusion models, the latest Stable Diffusion 3.5 significantly reduces memory requirements. It is designed with a great architectural innovation by implementing the diffusion process in a latent space. Earlier models operate directly in image space.
Thanks to the technical breakthrough and its open-source nature, Stable Diffusion has soon attracted a much broader user base, including developers, researchers, individual creators, and enterprise users.
• Constantly Improving with the Version Updates. Since its initial release, this text-to-image generation model has undergone significant evolution. Main versions include Stable Diffusion 1.5, 2.0, 2.1, 3.0, and the latest 3.5 series. They have made substantial improvements in various aspects, including output quality, prompt understanding, and generation capabilities, among others.
• Multiple Model Versions. Several specialized models are designed to address different user needs. The latest base model is Stable Diffusion 3.5. It offers significant improvements over previous versions. There are currently four main versions in the Stable Diffusion family: Stable Diffusion 3.5 Large, Large Turbo, Medium, and Flash.
• Advanced Prompt Understanding. The current Stable Diffusion 3.5 features a sophisticated multi-text encoder architecture that enables it to process more complex and detailed prompts more effectively. It can process test descriptions up to 10,000 characters long. This enables users to provide more detailed descriptions. Meanwhile, Stable Diffusion can produce higher-quality, more accurate results.
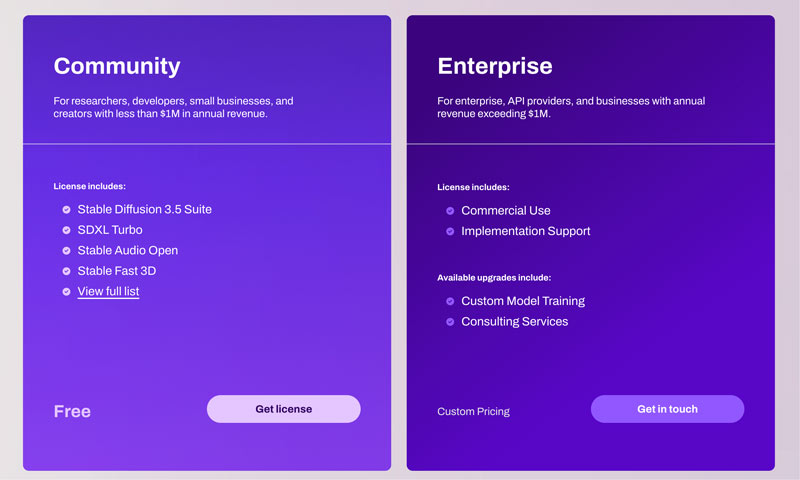
• Commercial and Creative Flexibility. Stable Diffusion 3.5 models are released under the Stability AI Community License and Enterprise License. That permits both commercial and non-commercial use. For most casual users, such as researchers, developers, and small businesses with annual revenues of less than $1M, they can use Stable Diffusion freely without restrictions. Users can freely adapt the AI to their specific needs and artistic styles.
As mentioned above, Stable Diffusion’s versatility makes it suitable for almost all users. Both developers, researchers, designers, digital artists, AI hobbyists, and even students can get significant benefits from its capabilities.
The latest Stable Diffusion 3.5 model has advanced capabilities to generate finer image details. Generated photos often have accurate lighting and subjects. Moreover, it can better fit the specific art style based on your prompts.
For most image generation models, areas like human hands and facial features can be particularly challenging. With the adoption of a 16-channel VAE, these common artifacts and imperfections can be effectively addressed. Stable Diffusion is good at rendering accurate lighting effects.
Despite these improvements, Stable Diffusion still has its weaknesses. The model continues to face certain challenges, particularly in full-body renders. Like other AI image generation models, Stable Diffusion often produces unexpected results, particularly when generating complete human figures. The current Stable Diffusion 3.5 performs well with close-up shots, portraits, and various non-human subjects.
The efficiency of Stable Diffusion varies depending on the specific model version used, hardware, output settings, and prompts. Generally, with a powerful NVIDIA GPU, you can easily generate a standard 1024x1024 image in 5-15 seconds. Better than many alternatives, Stable Diffusion allows users to train and fine-tune models on their own datasets. This is particularly valuable for professional users.
Compared to the previous models, the current Stable Diffusion 3.5 is much easier to use. However, the “easy” is highly relative to your technical skills, experience level, and chosen interface.
Multiple approaches are available for different technical comfort levels. Navigate to the official Stability AI website, get a license, and then submit a POST request as required.
Relatively speaking, thanks to various integrated solutions, the setup process of Stable Diffusion has been dramatically simplified. Moreover, Stable Diffusion has a WebUI that carries a comprehensive dashboard for better controlling the generation process. For an effective local deployment, it is also recommended to verify the suggested hardware requirements. For beginners, we recommend using Stable Diffusion on Windows 10 or 11.
Most active communities and platforms, such as Reddit, Discord, and forums, collect related techniques, creations, and problem-solving solutions about Stable Diffusion. This community-driven support ecosystem can rapidly share new models, features, practical workarounds, and other valuable resources.
| Feature/Model | Stable Diffusion | Midjourney | Seedance | VEO 3 |
| Pricing | Free, open-source model (Community License). Costs for hardware and cloud | Subscription: Around $10 – $$1,152/month | API: $0.09 – $1.50 per video | API: Gemini Developer API Pricing |
| Hardware Requirements | High (requires a powerful GPU) | Low (runs on Discord, no local hardware needed) | Cloud-based (No user hardware required) | Cloud-based (No user hardware required) |
| Customization | Extensive (Open-source, supports ControlNet, LoRA, and custom model training) | Limited (Through prompts and basic parameters) | Extensive (through prompts and creative controls) | Limited (Primarily in prompts) |
| Image/Video Quality | High upper limit, depends on models and tuning | High default quality, strong artistic style | High-definition 1080p videos | 8-second 720p to 1080p videos |
| Text Understanding | Good, be trained and enhanced with custom models | Excellent | Excellent, understands complex prompts | Excellent, understands complex narratives |
| Ease of Use | Steeper learning curve | Easy | API-based, requires integration | Easy, needs integration |
Stable Diffusion is a good choice for specific user groups, mainly those with technical skills and customization requirements. It offers capabilities that justify its steeper learning curve and hardware requirements. However, for beginners, many competitors provide a much easier setup and use experience. If you have compatible hardware and sufficient motivation to learn, Stable Diffusion is a flexible and creative tool for AI image generation.
Question 1. How much does Stable Diffusion cost?
Stability AI offers a Community License for developers, researchers, small businesses, and creators to use the Core Models (including Stable Diffusion 3) for free, unless your business is making over USD $1M of annual revenue or you are using the Stable Diffusion models for a commercial purpose. Generally, the Core Models and Derivative Works are free for you to use. You enter the required information and then submit a request for the free Community License. Read this article to get more free AI image generators!
Question 2. Are there hardware requirements for Stable Diffusion?
When you want to run Stable Diffusion on your computer, the user experience depends heavily on the hardware, especially the GPU, RAM, and CPU. You should have an NVIDIA graphics card. NVIDIA’s CUDA technology is designed with advanced acceleration technology. It can be the most compatible option for running Stable Diffusion. AMD graphics cards are often not recommended due to a lack of optimization.
Question 3. Is Stable Diffusion ideal for beginners?
Getting started with Stable Diffusion has become much easier thanks to one-click installation packages and cloud services. However, for beginners, the process still involves a learning curve, let alone mastering its full potential. Whether you choose the local installation or its cloud service, after running Stable Diffusion, you can interact with it through a WebUI. The Web User Interface has a visual interface for text-to-image and image-to-image functions. You can use them to generate and modify images. Moreover, you will often need to give detailed text descriptions to produce desired images. The final quality of your generated image heavily depends on the prompts you provide.
Question 4. What types of images can Stable Diffusion produce?
Stable Diffusion can generate images in a vast range of types. Most art styles are supported, including realistic pictures, anime, oil painting, watercolor, and others. The outputs are primarily determined by the specific AI model used and the prompts provided.
First, you need to choose a Checkpoint model. The model determines the core style of the generated image, such as whether it will be realistic or cartoon. You can search for and download related models from community platforms, such as Hugging Face. Then, refine it with smaller models.
Question 5. Can I use Stable Diffusion for commercial purposes?
Yes, you can use Stable Diffusion for commercial purposes. However, please verify the specific terms of the Stable Diffusion version you are using on the official website. The rules may have changed across different model versions. Moreover, you should ensure your planned commercial use does not violate the license’s prohibited activities. Additionally, be aware of the potential lack of copyright protection for the images you generate.
Conclusion
This Stable Diffusion review gives you a detailed introduction to Stability AI’s text-to-image generation model, especially for the latest Stable Diffusion 3.5 model. You should have a clear look at its capabilities, performance, strengths, and weaknesses through the review. By the end of this post, you should know precisely what Stable Diffusion can do for you and whether it is worth your time.
Did you find this helpful?
477 Votes

Adobe AI Image Generator Review: Overview and Pros & Cons
AI
Bing AI Image Generator: An In-Depth Look on Image Creator
AI
Ultimate Review of Craiyon, AI Image Generator Features
AI
Master DALL-E AI Image Generator: Revolutionize Your Visuals
AIAiseesoft AI Photo Editor is an advanced desktop application designed to enhance, upscale, and cutout images.


