Điểm nổi bật: Trò chuyện bằng AI , các trò chơi như Retro , thay đổi vị trí , Roblox đã được mở khóa
Điểm nổi bật: Trò chuyện bằng AI , các trò chơi như Retro , thay đổi vị trí , Roblox đã được mở khóa
Thế giới tạo giọng nói bằng AI đã chứng kiến những bước tiến vượt bậc, thay đổi cách chúng ta nghe và tương tác với công nghệ. Trình tạo giọng nói AI sử dụng các thuật toán trí tuệ nhân tạo tiên tiến để tạo ra những giọng nói sống động và giàu cảm xúc có thể được dùng cho nhiều ứng dụng khác nhau. Dù là cho trợ lý cá nhân, sáng tạo nội dung âm thanh hay tổng hợp giọng nói trong nhiều ngành công nghiệp, các công cụ này đều mang lại tính chân thực và linh hoạt đáng kinh ngạc. Bài viết toàn diện này giới thiệu về 7 Trình Tạo Giọng Nói AI Hàng Đầu hiện có, phân tích tính năng, ưu điểm, nhược điểm và các bước đơn giản để sử dụng chúng hiệu quả. Bằng cách hiểu rõ những điểm nổi bật riêng của từng công cụ, người dùng có thể đưa ra quyết định phù hợp dựa trên nhu cầu và yêu cầu cụ thể của mình.

Siri là trợ lý giọng nói do Apple phát triển, được thiết kế để cung cấp hỗ trợ được cá nhân hóa và thực hiện các tác vụ khác nhau thông qua khẩu lệnh. nó sử dụng các thuật toán máy học và xử lý ngôn ngữ tự nhiên tiên tiến khi chúng tôi hiểu và phản hồi các yêu cầu của người dùng. Điều tốt nhất về Siri là nó là trình tạo giọng nói AI miễn phí cho người dùng iPhone.
Mặc dù Siri chủ yếu hoạt động như một trợ lý giọng nói AI, nhưng nó cũng bao gồm một bộ tạo giọng nói có thể tạo ra giọng nói có âm thanh tự nhiên. Trình tạo giọng nói của Siri được biết đến với đầu ra rõ ràng, mượt mà và chất lượng cao. Nó sử dụng các kỹ thuật học sâu để tạo ra giọng nói giống con người, cho phép người dùng tương tác với Siri thông qua lệnh thoại và nhận phản hồi một cách tự nhiên và trực quan. Tuy nhiên, trình tạo giọng nói của Siri thiếu các tùy chọn tùy chỉnh mở rộng. Người dùng không thể sửa đổi đặc điểm giọng nói, trọng âm hoặc kiểu giọng nói. Nó có tính năng thay đổi giọng nói AI nếu bạn sẽ thay đổi nó theo cách thủ công theo sở thích của mình. Ngoài ra, sự phụ thuộc vào kết nối internet: Siri phụ thuộc rất nhiều vào kết nối internet để tạo đầu ra giọng nói. Đây có thể là một nhược điểm khi sử dụng Siri ở những khu vực có kết nối internet kém hoặc không có.

Phù Hợp Nhất Cho: Siri phù hợp nhất với người dùng iOS muốn sử dụng lệnh thoại cho các tác vụ như gọi điện, gửi tin nhắn, tạo lời nhắc, tìm đường đi và truy cập thông tin rảnh tay.
Nền Tảng: Siri có sẵn trên các thiết bị iOS, bao gồm iPhone, iPad và iPod Touch, cũng như loa thông minh HomePod của Apple.
Giá: Siri được cài đặt sẵn và miễn phí trên các thiết bị Apple tương thích.
Các Bước Đơn Giản
Hãy Kích Hoạt Siri bằng cách nhấn và giữ nút Home (trên các thiết bị iOS đời cũ) hoặc nút Bên (trên iPhone đời mới không có nút home) hoặc dùng lệnh thoại Hey Siri.
Khi Siri được kích hoạt, chờ tín hiệu thoại rồi đặt câu hỏi hoặc đưa ra lệnh. Ví dụ, bạn có thể nói, Thời tiết hôm nay thế nào? hoặc Gửi tin nhắn cho John.
Siri sẽ xử lý yêu cầu của bạn và đưa ra phản hồi hoặc thực hiện hành động được yêu cầu.
Murf.ai là trình tạo giọng nói AI chuyển văn bản thành giọng nói sử dụng các thuật toán nâng cao để chuyển đổi văn bản viết thành lời nói có âm thanh tự nhiên. Nó cung cấp tổng hợp giọng nói chất lượng cao và một loạt các tùy chọn giọng nói có thể tùy chỉnh để phù hợp với các ứng dụng khác nhau. Hơn thế nữa, Murf.ai là một trình tạo giọng nói AI chuyên tạo giọng nói tùy chỉnh, được cá nhân hóa. Nó sử dụng các thuật toán học sâu để phân tích và bắt chước các đặc điểm giọng nói độc đáo của một người, cho phép người dùng tạo ra lời nói gần giống với giọng nói của họ. Công nghệ của Murf.ai được thiết kế để nắm bắt các sắc thái, ngữ điệu và kiểu giọng nói tinh tế, dẫn đến đầu ra giọng nói có độ chân thực cao và được cá nhân hóa. Tuy nhiên, Murf.AI yêu cầu người dùng cung cấp các mẫu giọng nói đã ghi âm của họ để tạo giọng nói được cá nhân hóa. Điều này có thể gây lo ngại về quyền riêng tư cho những cá nhân ngần ngại chia sẻ dữ liệu giọng nói của họ với các dịch vụ của bên thứ ba.

Phù Hợp Nhất Cho: murf.ai phù hợp với cá nhân và doanh nghiệp đang tìm kiếm các giải pháp tổng hợp giọng nói đáng tin cậy. Nó có thể dùng trong nhiều lĩnh vực như đọc sách nói, sản xuất lồng tiếng, trợ lý ảo và các ứng dụng hỗ trợ tiếp cận.
Nền Tảng: murf.ai là nền tảng dựa trên web, truy cập qua trình duyệt trên máy tính và thiết bị di động. Mức giá dao động từ $20 đến $99.
Giá: murf.ai cung cấp các gói thuê bao theo tầng, dựa trên mức sử dụng và tính năng.
Các Bước Đơn Giản
Truy cập trang web murf.ai và tạo tài khoản hoặc đăng nhập nếu bạn đã có.
Truy cập giao diện chuyển văn bản thành giọng nói để nhập đoạn văn bản mong muốn chuyển thành giọng nói.
Tùy chỉnh các tham số giọng nói như cao độ, tốc độ và cảm xúc theo sở thích của bạn.
Nhấp vào nút Generate hoặc Play để bắt đầu quá trình tổng hợp giọng nói.
Sau khi quá trình tạo giọng nói hoàn tất, bạn có thể xem trước và tải xuống tệp giọng nói đã tổng hợp ở nhiều định dạng khác nhau.
Lyrebird là một trình tạo giọng nói AI nổi tiếng với khả năng tái tạo giọng nói của con người với độ chính xác ấn tượng. Đó là lý do tại sao nó được gắn thẻ là Bản sao giọng nói AI tốt nhất. Bằng cách sử dụng các kỹ thuật học sâu, Lyrebird có thể tạo ra lời nói gần giống với một cá nhân cụ thể hoặc bắt chước giọng nói của một người dựa trên một vài phút âm thanh được ghi lại của họ. Nó đã được sử dụng cho nhiều ứng dụng khác nhau, bao gồm thuyết minh, trợ lý ảo và các dịch vụ trợ năng. Tóm lại, Lyrebird là một nền tảng tạo giọng nói AI cung cấp giọng nói tổng hợp chân thực và có thể tùy chỉnh. Nó sử dụng các thuật toán hiểu biết sâu để phân tích và bắt chước các mẫu giọng nói của con người, cho phép người dùng tạo ra giọng nói chất lượng cao cho các ứng dụng khác nhau.
Mặt khác, khả năng bắt chước giọng nói của Lyrebird AI với độ chính xác cao làm dấy lên những lo ngại về đạo đức. Nó có khả năng bị lạm dụng, chẳng hạn như mạo danh giọng nói hoặc tạo giọng nói tổng hợp mà không có sự đồng ý. Ngoài ra, một vấn đề sở hữu trí tuệ có sẵn. Công nghệ của Lyrebird AI cho phép người dùng sao chép và sử dụng giọng nói của người khác mà không được phép. Điều này có thể dẫn đến tranh chấp bản quyền và sở hữu trí tuệ. Nhìn chung, công cụ này là một công cụ tái tạo giọng nói AI tuyệt vời.

Phù Hợp Nhất Cho: Lý tưởng cho nhà phát triển, người sáng tạo nội dung và doanh nghiệp muốn có các giọng nói tổng hợp giống thật, có thể tùy chỉnh. Nó có thể được dùng trong trợ lý giọng nói, sản xuất nội dung âm thanh, trải nghiệm thực tế ảo và hơn thế nữa.
Nền Tảng: Lyrebird là nền tảng dựa trên web, truy cập qua trình duyệt trên máy tính bàn và điện thoại di động.
Giá: $18.00
Các Bước Đơn Giản
Đăng nhập vào tài khoản Lyrebird sau khi tạo. Sau đó mở cửa sổ Voice Generation và nhập đoạn văn bản cần chuyển thành giọng nói.
Chọn chất lượng giọng nói mong muốn, chẳng hạn như giới tính, tuổi tác và phong cách cảm xúc.
Nhấp vào nút Generate hoặc Play để bắt đầu quá trình tạo giọng nói.
WaveNet là một trình tạo giọng nói AI dựa trên học tập sâu được phát triển bởi DeepMind, một công ty con của Google. Nó sử dụng một kỹ thuật được gọi là mô hình tổng quát để tổng hợp lời nói có âm thanh tự nhiên và thực tế cao. WaveNet nổi tiếng với khả năng ghi lại các chi tiết nhỏ trong lời nói của con người, bao gồm ngữ điệu, hơi thở và thậm chí cả tiếng ồn xung quanh, dẫn đến đầu ra giọng nói có tính biểu cảm cao và sống động như thật. Tuy nhiên, quá trình tạo giọng nói của WaveNet AI có thể tốn nhiều công sức tính toán, đòi hỏi thời gian và sức mạnh xử lý đáng kể để tạo ra đầu ra chất lượng cao. Điều này có thể hạn chế khả năng áp dụng thời gian thực của nó trong một số tình huống nhất định. Nó cũng thiếu kiểm soát chi tiết. Quá trình tạo giọng nói của WaveNet AI dựa trên các mô hình học sâu không cung cấp khả năng kiểm soát chi tiết đối với việc sửa đổi các đặc điểm giọng nói cụ thể. Điều thú vị về nó là nó có thể là một trình tạo giọng rapper AI nếu chúng ta đặt nó trên cài đặt của nó. Người dùng có khả năng hạn chế để tùy chỉnh giọng nói được tạo ngoài dữ liệu đào tạo. Hơn nữa, nó sử dụng kiến trúc mạng thần kinh sâu để tạo ra các dạng sóng lời nói có tính biểu cảm và tự nhiên cao, khiến nó ít nhất là tốt nhất.
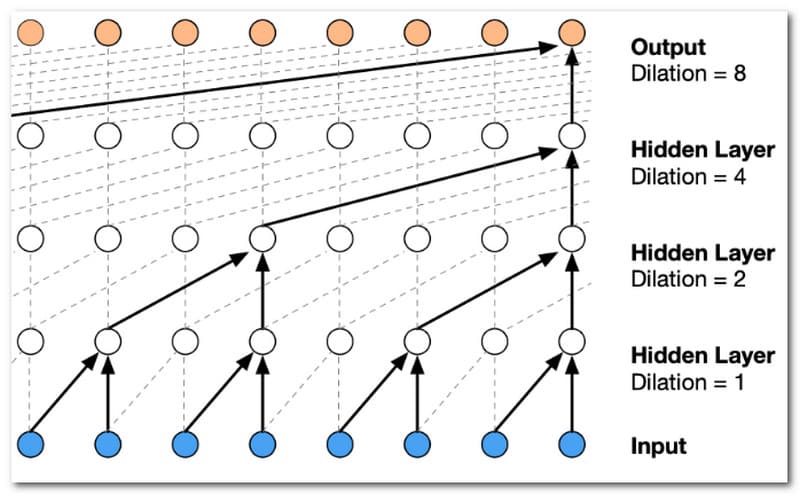
Phù Hợp Nhất Cho: WaveNet phù hợp nhất với các ứng dụng tổng hợp giọng nói có độ trung thực cao và giống người. Nó thường được dùng trong trợ lý ảo, sản xuất lồng tiếng, đọc sách nói và các tình huống khác nơi giọng nói tự nhiên là yếu tố then chốt.
Nền Tảng: WaveNet là một công nghệ có thể được tích hợp vào nhiều nền tảng và ứng dụng. Nó đã được triển khai trong các dịch vụ như Google Assistant và cũng có sẵn dưới dạng API để nhà phát triển tích hợp vào dự án của họ.
Giá: Giá của WaveNet thay đổi tùy theo cách triển khai hoặc tích hợp cụ thể. Google cung cấp nhiều mô hình giá cho các dịch vụ khác nhau sử dụng WaveNet. Giá bắt đầu từ $4.0.
Các Bước Đơn Giản
Xác định nền tảng hoặc ứng dụng cụ thể đang sử dụng WaveNet để tạo giọng nói.
Nếu dùng nền tảng tích hợp như Google Assistant, hãy kích hoạt tính năng nhập liệu bằng giọng nói hoặc kích hoạt chức năng lệnh thoại.
Nói hoặc cung cấp kiểu nhập văn bản mà bạn muốn tổng hợp thành giọng nói.
Nền tảng hoặc ứng dụng sẽ xử lý đầu vào bằng thuật toán của WaveNet và tạo dạng sóng giọng nói tương ứng. Bài phát biểu được tổng hợp sẽ được phát lại hoặc sử dụng theo yêu cầu trong nền tảng hoặc ứng dụng.
Amazon Polly là dịch vụ chuyển văn bản thành giọng nói dựa trên đám mây mà Amazon Web Services (AWS) cung cấp. Nó cung cấp giọng nói sống động như thật và khả năng tổng hợp giọng nói tiên tiến, cho phép các nhà phát triển và doanh nghiệp chuyển đổi văn bản thành giọng nói có âm thanh tự nhiên. Điều đó có nghĩa là nó cũng có thể được sử dụng như một trình đọc giọng nói AI. Amazon Polly cung cấp nhiều loại giọng nói bằng nhiều ngôn ngữ và cung cấp cho nhà phát triển các API dễ sử dụng để tích hợp khả năng tạo giọng nói vào ứng dụng của họ. Nó cung cấp tính năng tổng hợp giọng nói chất lượng cao với nhiều tùy chọn tùy chỉnh khác nhau.

Phù Hợp Nhất Cho: Amazon Polly lý tưởng cho nhà phát triển và doanh nghiệp muốn có giải pháp chuyển văn bản thành giọng nói có khả năng mở rộng và tùy chỉnh. Nó có thể dùng trong các ứng dụng như trợ lý giọng nói, nền tảng e-learning, sản xuất podcast, tính năng hỗ trợ tiếp cận và nhiều hơn nữa.
Nền Tảng: Amazon Polly là dịch vụ đám mây, truy cập qua AWS Management Console hoặc thông qua API ở dạng lập trình.
Giá: $40.00. Amazon Polly dùng mô hình trả tiền theo mức sử dụng, tính phí dựa trên số lượng ký tự được xử lý và giọng đọc được chọn. Tham khảo tài liệu giá của Amazon Polly để biết thông tin chi tiết.
Các Bước Đơn Giản
Cách tạo giọng nói AI với Polly như sau. Đăng nhập AWS Management Console hoặc dùng Amazon Polly API để bắt đầu.
Đối với tổng hợp giọng nói, chọn Giọng đọc và Ngôn ngữ mong muốn.
Nhập văn bản sẽ được chuyển đổi thành giọng nói theo cách thủ công hoặc theo chương trình.
Gọi phương thức API phù hợp hoặc nhấp vào nút liên quan trong console để Bắt đầu quá trình chuyển văn bản thành giọng nói.
Baidu Research đã phát triển Deep Voice, một kỹ thuật tổng hợp giọng nói dựa trên AI. Các kỹ thuật học sâu tạo ra giọng nói chân thực và biểu cảm từ đầu vào văn bản. Deep Voice AI là một trình tạo giọng nói AI do OpenAI phát triển, sử dụng các kỹ thuật học sâu để tạo ra giọng nói giống con người. Nó sử dụng kết hợp mạng thần kinh và thuật toán tổng hợp giọng nói để tạo ra giọng nói tự nhiên. Deep Voice AI có thể học hỏi từ các bộ dữ liệu lớn và tạo giọng nói bằng nhiều ngôn ngữ với các kiểu giọng nói và trọng âm khác nhau.

Phù Hợp Nhất Cho: Deep Voice phù hợp với các ứng dụng cần tổng hợp giọng nói chất lượng cao và có thể tùy chỉnh. Nó có thể dùng trong trợ lý ảo, sản xuất lồng tiếng, lồng tiếng phim và các tình huống khác nơi giọng nói chân thực, giống người là rất quan trọng.
Nền Tảng: Deep Voice là công nghệ có thể tích hợp vào nhiều nền tảng và ứng dụng. Thông thường nó được triển khai dạng API để nhà phát triển tận dụng và tích hợp chức năng Deep Voice vào dự án của họ.
Giá: $19
Các Bước Đơn Giản
Xác định đoạn văn bản bạn muốn chuyển thành giọng nói bằng Deep Voice AI. Chuẩn bị văn bản bằng lập trình trong ứng dụng của bạn hoặc từ dữ liệu người dùng nhập vào.
Tạo một yêu cầu API để gửi văn bản đến Deep Voice AI API cho việc tổng hợp giọng nói.
Khi nhận được phản hồi API, hãy xử lý tệp âm thanh giọng nói đã được tổng hợp.
Resemble AI là một nền tảng tổng hợp giọng nói do AI cung cấp, cho phép người dùng tạo giọng nói chân thực và được cá nhân hóa cho các ứng dụng khác nhau. Nó sử dụng các kỹ thuật tổng hợp giọng nói AI và học sâu để tạo ra giọng nói chất lượng cao, có âm thanh tự nhiên. Resemble AI là trình tạo giọng nói AI chuyên tạo giọng nói tùy chỉnh cho các ứng dụng khác nhau, chẳng hạn như trợ lý ảo, trò chơi và sản xuất phương tiện. Nó sử dụng các thuật toán học sâu để phân tích và tái tạo các đặc điểm độc đáo trong giọng nói của một người. Công nghệ Resemble AI cho phép người dùng tạo giọng nói AI tổng hợp gần giống với các cá nhân cụ thể, dẫn đến đầu ra giọng nói chân thực và được cá nhân hóa cao. Nó cung cấp giao diện thân thiện với người dùng và cung cấp cho nhà phát triển API để tích hợp khả năng tạo giọng nói vào dự án của họ.

Phù Hợp Nhất Cho: Resemble AI phù hợp với cá nhân, nhà phát triển và doanh nghiệp đang tìm kiếm các giải pháp tổng hợp giọng nói biểu cảm, có thể tùy chỉnh. Nó có thể được dùng trong sản xuất lồng tiếng, trợ lý ảo, game, hoạt hình, đọc sách nói và các ứng dụng khác nơi cần những giọng đọc độc đáo, cá nhân hóa.
Nền Tảng: Resemble AI là nền tảng đám mây cung cấp API và SDK để dễ dàng tích hợp vào nhiều nền tảng và ngôn ngữ lập trình khác nhau.
Giá: $29.00
Các Bước Đơn Giản
Tạo một tài khoản trên trang web Resemble AI và lấy thông tin xác thực API cần thiết.
Chọn mức sửa đổi giọng nói mong muốn và thu thập mọi dữ liệu đào tạo cần thiết. Sau đó, cài đặt Resemble AI SDK hoặc thư viện cho ngôn ngữ lập trình bạn chọn.
Sử dụng thông tin đăng nhập được cung cấp, xác thực các truy vấn API của bạn. Gửi văn bản và các tham số tùy chỉnh tới nền tảng Resemble AI thông qua API hoặc SDK. Cuối cùng, truy xuất đầu ra giọng nói đã tổng hợp và sử dụng nó khi cần trong ứng dụng hoặc dịch vụ của bạn.
Voice.ai có an toàn không?
Theo người dùng, một số AI bằng giọng nói an toàn khi sử dụng trong khi các công cụ khác thì không. Để đánh giá mức độ an toàn của một nền tảng hoặc trang web như Voice.ai, bạn nên tiến hành nghiên cứu kỹ lưỡng, đọc các bài đánh giá và lời chứng thực của người dùng, đánh giá các chính sách quyền riêng tư và điều khoản dịch vụ của họ, đồng thời xem xét các yếu tố như danh tiếng của nền tảng, các biện pháp bảo mật và hỗ trợ khách hàng. Bạn cũng có thể kiểm tra xem các cơ quan đáng tin cậy đã xác minh nền tảng hay có bất kỳ chứng nhận nào cho thấy tính hợp pháp và cam kết của nền tảng đối với sự an toàn của người dùng.
Voice.ai có hợp pháp không?
Đầu tiên và quan trọng nhất, AI của chúng ta lên tiếng hợp pháp? Câu trả lời nhanh là có. Tuy nhiên, có nhiều hơn thế. Tính hợp pháp của công nghệ này khác nhau tùy thuộc vào cách nó được sử dụng và quyền tài phán được đề cập.
Các trình tạo giọng nói AI có thể được dùng để làm gì?
Trình tạo giọng nói AI có nhiều ứng dụng. Chúng có thể được sử dụng để sản xuất thuyết minh trong phim, chương trình truyền hình và quảng cáo, tạo trợ lý ảo với giọng nói độc đáo, thêm tường thuật vào sách nói, cải thiện khả năng tiếp cận cho người khiếm thị, nâng cao trải nghiệm chơi trò chơi với giọng nói nhân vật tương tác và chân thực, v.v. Ngoài ra, nếu bạn đã quen thuộc với trình tạo Giọng nói AI của Burger King, thì nó chủ yếu được sử dụng để tùy chỉnh giọng nói, quảng cáo, podcasting, nghe sách nói như Diễn viên lồng tiếng Hayasaka, v.v. Một số khác là Val Kilmer AI Voice, đề xuất tiếp tục các dự án của mình sau khi chẩn đoán ung thư. Thật vậy, nó rất hữu ích cho các mục đích khác nhau.
Các giọng nói do AI tạo ra có không thể phân biệt với giọng người thật không?
Mặc dù giọng nói do AI tạo ra đã được cải thiện đáng kể trong những năm gần đây, nhưng chúng vẫn có thể có những điểm khác biệt nhỏ mà người nghe đã qua đào tạo có thể phát hiện ra. Tuy nhiên, những tiến bộ trong việc tạo giọng nói AI tiếp tục thu hẹp khoảng cách giữa giọng nói tổng hợp và giọng nói của con người, khiến sự khác biệt ít được chú ý hơn trong nhiều trường hợp.
Các trình tạo giọng nói AI có thể bắt chước giọng nói cụ thể không?
Một số trình tạo giọng nói AI có thể bắt chước các giọng nói cụ thể, chẳng hạn như những người nổi tiếng hoặc nhân vật lịch sử của trình tạo giọng nói Ai, bằng cách huấn luyện các mô hình trên dữ liệu được nhắm mục tiêu. Chúng ta có giọng nói AI của Joe Biden, giọng nói Ai của Trump, giọng nói của Elon Musk và những người khét tiếng hơn để làm ví dụ cụ thể. Tuy nhiên, chất lượng và độ chính xác của tính năng bắt chước giọng nói có thể khác nhau tùy thuộc vào dữ liệu đào tạo có sẵn và độ phức tạp của giọng nói được sao chép. Đó là lý do tại sao AI Voice Meme hoàn toàn không được khuyến khích.
Phần kết luận
Tóm lại, việc tạo giọng nói AI cung cấp nhiều công cụ và nền tảng khác nhau cho phép người dùng tạo giọng nói tổng hợp chất lượng cao cho các ứng dụng khác nhau. Mỗi công cụ đều có những tính năng, ưu điểm và hạn chế riêng. Khi chọn trình tạo giọng nói AI tốt nhất cho nhu cầu của mình, bạn phải xem xét giá cả, khả năng tương thích nền tảng, tính dễ sử dụng, chất lượng giọng nói và các tùy chọn tùy chỉnh. Bài viết này đã khám phá một số công cụ tạo giọng nói AI nổi bật, bao gồm Siri, murf.ai, Lyrebird, WaveNet, Amazon Polly, Deep Voice và Resemble AI. Mỗi công cụ đều có điểm mạnh và điểm yếu, phục vụ cho yêu cầu và sở thích của người dùng.
Tìm thấy điều này hữu ích không bạn?
391 Phiếu bầu

Đánh giá Character.AI: Giải phóng sức sáng tạo trong thế giới AI
AI
Đánh giá chi tiết YouChat: Công cụ AI đáng kinh ngạc dành cho mọi người
AI
Đánh giá ChatGPT: Trợ lý AI có an toàn và hiệu quả không?
AI
Đánh giá trực tuyến 9 Chatbot AI hàng đầu: Tính năng, Giá cả, Ưu và nhược điểm
AIBộ chuyển đổi video tất cả trong một, trình chỉnh sửa, trình tăng cường được nâng cấp bằng AI.


